WACV 2025

March 1-3, 2025 in Tucson, Arizona | Booth #202
We’re excited to announce our participation in the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2025, happening February 28 – March 4 in Tucson, Arizona! As a premier international event for computer vision enthusiasts and professionals, WACV highlights groundbreaking AI research, innovative applications, and a wealth of knowledge through its main conference, co-located workshops, and tutorials. Be sure to visit us at Booth #202 to explore how Kitware is driving innovation in this ever-evolving field.
Kitware has been a proud and active participant at WACV for years, contributing to the event as exhibitors, co-organizers, and through our involvement in workshops, paper presentations, and committees. This year is no different, with several of our team members taking on key roles:
- Anthony Hoogs, Ph.D. served on the WACV awards committee, and is on the advisory committee for the Workshop on Real-World Surveillance: Applications and Challenges.
- Scott McCloskey, Ph.D. is lending his expertise as an area chair, the government relations chair, and co-chair of the Workshop on Applications of Computational Imaging.
- Brian Clipp, Ph.D. and Christopher Funk, Ph.D. are serving as area chairs, with Brian taking on additional responsibilities as the demo chair.
Kitware will also showcase our cutting-edge expertise in computer vision and AI with three papers in the main conference and an official demonstration. Come and see how our innovative open source tools and customized solutions are helping to shape the future of AI and computer vision.
Kitware’s Papers and Demonstrations
MetaVIn: Meteorological and Visual Integration for Atmospheric Turbulence Strength Estimation
Accepted Paper
Authors: Ripon Saha, Scott McCloskey, Suren Jayasuriya
Long-range image understanding is a challenging task for computer vision due to the presence of atmospheric turbulence. Turbulence can degrade image quality (blur and geometric distortion) due to the medium’s spatio-temporal varying index of refraction bending light rays. The strength of atmospheric turbulence is quantified by the refractive index structure parameter C 2n, and estimating it is important both as an indicator of image degradation and is useful for downstream tasks including video restoration and estimating true shape and range/depth. However, traditional methods for estimating C 2n involve expensive and complex optical equipment, limiting their practicality. In this paper, we propose MetaVIn: a Meteorological and Visual Integration system to predict atmospheric turbulence strength. Our method leverages image quality metrics to capture sharpness and blur, combined with meteorological information within a Kolmogorov Arnold Network (KAN). We demonstrate that this approach provides a more accurate and generalizable estimation of C 2n, outperforming previous state-of-the-art methods in both blind image quality assessment and passive video-based turbulence strength estimation on a large dataset of over 30,000 image samples with accompanying ground truth scintillometer measurements for C 2n. Our method enables better prediction and mitigation of atmospheric image degradation while being useful in applications such as shape and range estimation, enhancing the practical utility of our approach.

Re-identifying People in Video via Learned Temporal Attention and Multi-modal Foundation Models
Accepted Paper
Authors: Cole Hill, Flori Yellin, Krishna Regmi, Dawei Du, Scott McCloskey
Biometric recognition from security camera video is a challenging problem when the individuals change clothes or when they are partly occluded. Others have recently demonstrated that CLIP’s visual encoder performs well in this domain, but existing methods fail to make use of the model’s text encoder or temporal information available in video. In this paper, we present VCLIP, a method for person identification in videos captured in challenging poses and with changes to a person’s clothing. Harnessing the power of pre-trained vision-language models, we jointly train a temporal fusion network while fine-tuning the visual encoder. To leverage the cross-modal embedding space, we use learned biometric pedestrian attribute features to further enhance our model’s person re-identification (Re-ID) ability. We demonstrate significant performance improvements via experiments with the MEVID and CCVID datasets, particularly in the more challenging clothes-changing conditions. In support of this and future methods that use textual attributes for Re-ID with multimodal models, we release a dataset of annotated pedestrian attributes for the popular MEVID dataset.

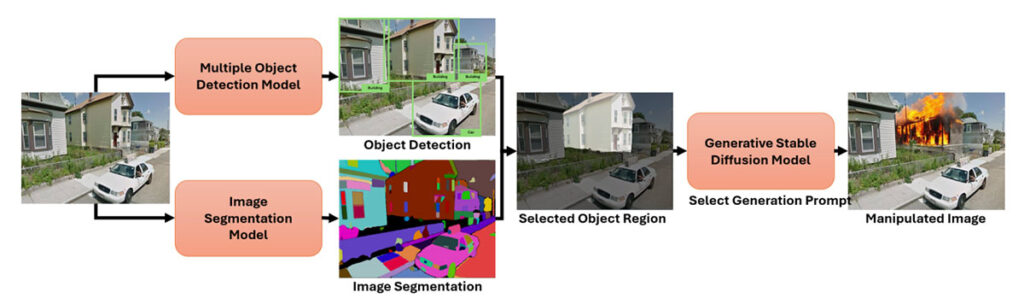
A Semantically Impactful Image Manipulation Dataset: Characterizing Image Manipulations using Semantic Significance
Accepted Paper
Authors: Yuwei Chen, Ming-Ching Chang, Mattias Kirchner, Zhenfei Zhang, Xin Li, Arslan Basharat, Anthony Hoogs
We investigate how to characterize semantic significance (SS) in detecting image manipulations (IMD) for media forensics. We introduce the Characterization of Semantic Impact for IMD (CSI-IMD) dataset, which focuses on localizing and evaluating the semantic impact of image manipulations to counter advanced generative techniques. Our evaluation of 10 state-of-the-art IMD and localization methods on CSI-IMD reveals key insights. Unlike existing datasets, CSI-IMD provides detailed semantic annotations beyond traditional manipulation masks, aiding in the development of new defensive strategies. The dataset features manipulations from advanced generation methods, offering various levels of semantic significance. It is divided into two parts: a gold-standard set of 1,000 manually annotated manipulations with high-quality control, and an extended set of 500,000 automated manipulations for large-scale training and analysis. We also propose a new SS-focused task to assess the impact of semantically targeted manipulations. Our experiments show that current IMD methods struggle with manipulations created using stable diffusion, with TruFor and Cat-Net performing the best among those tested. The CSI-IMD dataset will become available at https://github.com/csiimd/csiimd.
Demonstrating Accurate & High Frequency Star Tracking with Event-Based Sensing
Live Demonstration
Presenters: Dennis Melamed, Albert W. Reed, Connor Hashemi, Nitesh Menon, and Scott McCloskey
Kitware has developed a novel algorithm for event-based star tracking that delivers high-frequency updates, low latency, and superior motion tolerance compared to traditional methods. Using event-based sensors (EBS) and an extended Kalman filter (EKF), our system accurately estimates orientation, even under rapid motion, and operates efficiently on low SWaP (size, weight, and power) hardware—making it ideal for resource-constrained environments.
In our live demo, a battery-powered event camera and processor module mounted on a pan/tilt mechanism will showcase the algorithm in action. Attendees will see real-time comparisons between the system’s orientation estimates and those from the pan/tilt encoders, along with a GUI that visualizes event streams, star associations, and processing metrics. For those unable to attend, our results show that the algorithm’s estimated orientation remains within 100 arcseconds of a commercial star tracker with flight heritage and performs effectively at motion speeds up to 7.5 deg/sec—significantly faster than conventional systems.

Kitware is hiring!
At Kitware, we’re not just advancing technology—we’re building a team of passionate innovators ready to make a difference. If you’re interested in joining a company where collaboration and innovation thrive, stop by our booth to learn more about our career opportunities.
With over three years of being recognized as a Great Place to Work®, we pride ourselves on fostering an environment where our team members feel empowered to grow, learn, and make meaningful contributions to cutting-edge projects. Whether you’re just starting your career or looking for your next big challenge, Kitware offers opportunities to work on impactful solutions that shape the future.
To explore open positions and learn more about our company culture, visit our Careers page to see all of our benefits and learn what it’s like to work at Kitware. If you’re interested in applying for one of our open positions, please complete this form. Please note that most of our positions require U.S. citizenship.
Featured Open Positions
Computer Vision Researcher
Conduct research and develop robust solutions in the areas of vision-language models, object detection, activity detection, tracking, anomaly detection, open-world learning, multimedia forensics, explainable/ethical AI, and more.
3D Computer Vision Researcher
Conduct research and develop solutions for problems related to camera calibration, registration, structure from motion, neural rendering, neural implicit surfaces, surface meshing, and more.
Technical Leader of Natural Language Processing
Lead research and development with an emphasis on natural language processing, generative models, and AI. Pursue related research areas of growth with support and mentorship from the company leadership.
Natural Language Processing Researcher
Develop robust solutions in the areas of natural language processing, large language models (LLMs), foundation models, ML, and AI. Conduct research on content understanding, knowledge extraction, reasoning, decision-making, disinformation mitigation, and more. Opportunity to engage with the research community and to pursue new research directions.
Computer Vision & NLP Research Internships
Work with the AI researchers at Kitware and with our academic collaborators for 3-6 months, conduct research, and publish results at premier conferences. Open to Ph.D. students in natural language processing, computer vision, AI, and related fields.
Computer Vision at Kitware
Kitware is a leader in leveraging artificial intelligence and machine learning for computer vision. Our technical areas of focus include:
- Generative AI
- Multimodal large language models
- Deep learning
- Dataset collection and annotation
- Interactive Do-It-Yourself AI
- Explainable and ethical AI
- Object detection, classification, and tracking
- Complex activity, event, and threat detection
- Cyber-physical systems
- Disinformation detection
- 3D vision
- Super-resolution and enhancement
- Semantic segmentation
- Computational imaging
Kitware’s commitment to continuous exploration and participation in other research and development areas is unwavering. We are always ready to apply our technologies and tools across all domains, from undersea to space, to meet our customers’ needs.
We recognize the value of leveraging our advanced computer vision and deep learning capabilities to support academia, industry, and the DoD and intelligence communities. We work with various government agencies, such as the Defense Advanced Research Project Agency (DARPA), Air Force Research Laboratory (AFRL), the Office of Naval Research (ONR), Intelligence Advanced Research Projects Activity (IARPA), the National Geospatial Intelligence Agency (NGA), U.S. Army and the U.S. Air Force. We also partner with prestigious academic institutions on government contracts.
Kitware can help you solve your challenging computer vision problems using our software R&D expertise. Contact our team to learn more about how we can partner with you.