Spack CI (Part 1): Building Scalable Workflows Using Kubernetes for the Spack Package Manager
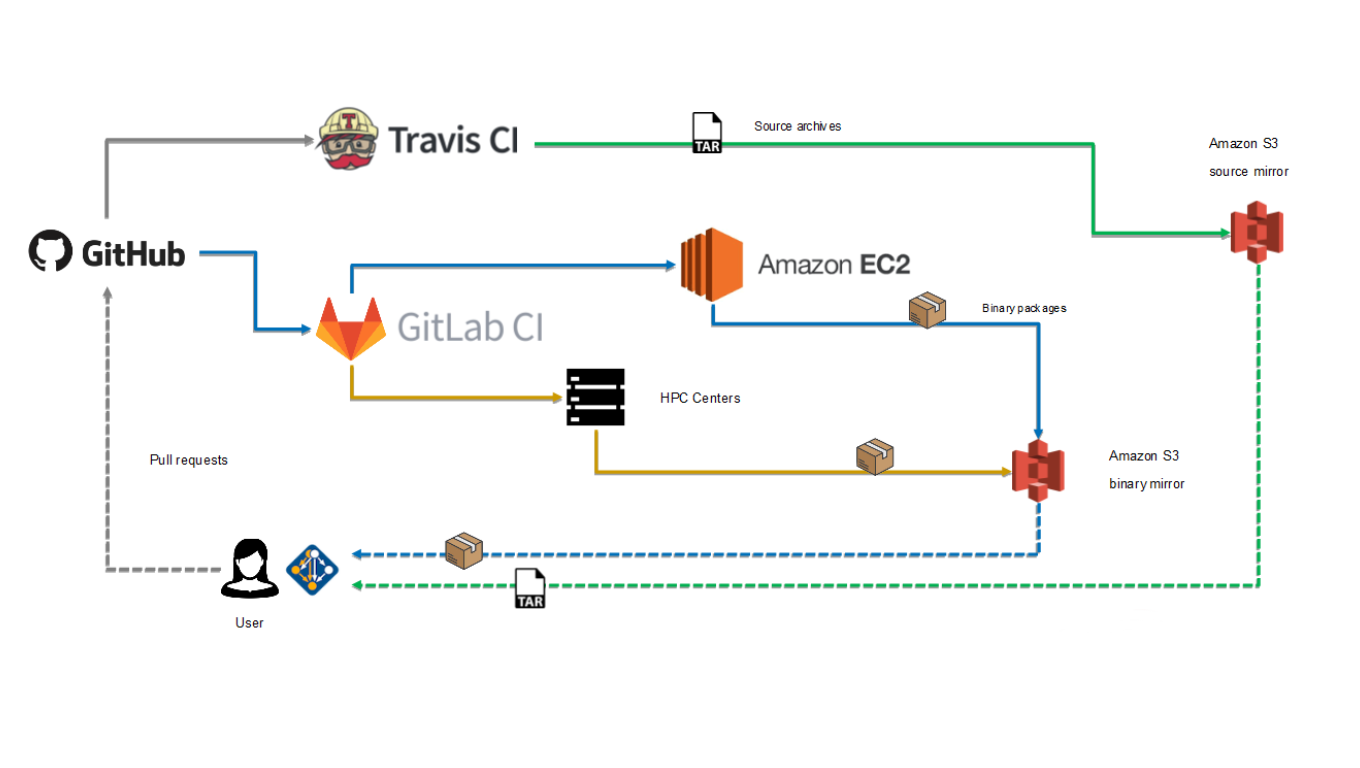
In this post, we describe how we were able to use Kubernetes to develop and deploy the infrastructure needed to support a custom software-build pipeline for the Spack (https://spack.io) project. Spack is a package manager for supercomputers, Linux and macOS. It makes installing scientific software easy. With Spack, you can build a package with multiple versions, configurations, platforms and compilers, and all of these builds can coexist on the same machine.
This post is the first in a series discussing various aspects of the Spack project, the build pipeline, and the roles they play in advancing the state of HPC software management. In this post, we introduce the Spack project and discuss how we leverage Kubernetes to help the Spack team meet their development and operational needs.
Introduction and Motivation
The technical state of software is constantly advancing, both in terms of the raw quantity of available software as well as the level of sophistication with which software is produced. With these advancements, most notably those in compiler technology and language design, software architects are better equipped than ever to express functionality and intent with extraordinary effectiveness and efficiency. It comes as no surprise that the mechanical task of translating these increasingly sophisticated expressions into a machine-executable form has also become more computationally expensive. Indeed, the effective management of modern software stacks has sufficiently grown in scope to become a technical computing challenge in its own right, and for large-scale HPC efforts, like the Exascale Computing Project (ECP), a joint effort of the US Department of Energy Office of Science (DOE-SC), and National Nuclear Security Administration (NNSA), the need for a comprehensive solution to this software management challenge is more pressing than ever before.
Led by LLNL, Spack is a software package manager with a number of advanced features that make it especially suitable for managing scientific computing software for supercomputers. Spack can also manage the same software packages on PCs running Linux or Mac. Users of Spack can build packages with multiple versions, configurations, platforms and compilers, all combinations of which can coexist, allowing users to install any number of them on a single system.
For this effort, the technical team is made up of Kitware engineers from the Software Process and Data and Analytics groups, and a group of core Spack developers at LLNL, with whom we collaborate both directly as well as through the ECP. Our primary goal is to extend Spack’s offerings to include a publicly available repository of pre-built binary packages from which Spack clients may download and install in lieu of compiling from source, which is how a software package is normally installed with Spack. Since directly compiling much of these software packages from source is very resource-intensive, it is important that pre-built packages be made available. With pre-built packages, engineers and scientists can use Spack to deploy and manage the software systems they need for their work without dedicating much time or resources to software assembly. This alternative can significantly minimize the extent to which package management disrupts their day-to-day operations, but it also benefits the greater HPC community; pre-built packages only need to be produced once and then can be shared, resulting in a time and resource savings that scale with the number of users.
This goal presents several unique challenges. The many variations with which packages may be built quickly leads to combinatorial growth in the number of individual build jobs for any particular release. These especially large workloads are challenging even when such variations are only considered over a relatively small number of axes, like package version, operating system, and architecture. Furthermore, the build jobs in these workloads are highly nonuniform, both in terms of their resource requirements as well as the dependency relationships that they share with other builds in the same workload. While some packages build fine with relatively few resources, others involve substantial build processes that require a considerable amount of compute and memory capacity, and the highly interdependent relationships many of these packages have with each other is likely to limit the benefits of any scheduling strategies that might help smooth out these nonuniformities. For these reasons, we must reckon with incredible temporal variation in resource demands, and seek solutions with a high degree of automation and flexibility in order to scale available resources up and down in response to this demand.
Our Approach
To meet these operational challenges, we chose Kubernetes (https://kubernetes.io) for its powerful automation and scaling capabilities. Using Kubernetes allows us to easily assemble our custom pipeline from several open-source components as well as host a number of miscellaneous services in support of the Spack project. Kubernetes provides the primitives for service orchestration and automation that we need to handle highly variable workloads, such as built-in container scheduling policies that can account for resource consumption on a per-container basis, and a resource model that can be easily extended to consider custom resources of interest, such as GPUs.
Our infrastructure is built upon AWS. We use their new EKS service to provision a highly available Kubernetes master and autoscaling groups in EC2 to provision worker instances that self-register to the master, forming the cluster. We use m4.xlarge instances to run the build jobs, and t2.medium instances to host most of the remaining services. Within the cluster, we deploy and manage Gitlab and Gitlab CI services for workload definition, scheduling and execution. The jobs in these workloads are tasked with building a package and produce two primary products. The first of these is the software binary package, which is then signed and uploaded to a public S3 bucket. The second is telemetry data collected during the build. This data is packaged and uploaded to a CDash instance that we also host on the cluster. This CDash instance serves as a useful point for collaboration, where Spack developers can keep up to date on what packages in a release are building, and investigate any issues that may be preventing other packages from building successfully.
Operations Case Study: Custom Autoscaling Strategies
Our choice to use Kubernetes brings significant benefits to many parts of the pipeline. One such example relates to how we approach autoscaling. Early on, we realized that naive autoscaling policies (i.e., autoscaling at the cloud-provider level based on average resource utilization) were not going to work well for our use case. Highly variable utilization is a concern even across a single build job, so we can not rely on average utilization to be a reliable indicator for when a change in capacity is necessary or appropriate. However, the greater issue with naive policies is that they require the underlying workload to be preemptable. We had a strong preference to avoid imposing this requirement, as it would have significantly complicated our process. It was clear that for our case, a successful autoscaling strategy needed to account for the state of any workloads, both pending and in progress, as well as which nodes are currently executing jobs.
To this end, we are currently experimenting with the implementation of a custom Kubernetes controller. A controller is a component in a Kubernetes cluster that monitors the cluster’s state and triggers various actions in response to changes in this state. To date, we have achieved workload-aware autoscaling with our own Kubernetes controller using a simple heuristic based on how many nodes are deployed, which are processing jobs, and how many jobs are pending. For future work in this area, we will explore the use of finer-grained utilization data collected from past builds to predict utilization profiles on a per-job basis. We hope to incorporate these a priori estimates into our controller and investigate the possibility of employing more cost-effective scheduling strategies.
Development Case Study: Leveraging Containers to Promote Software Reuse
While Kubernetes has proven instrumental in addressing our operational challenges, its comprehensive approach to container orchestration has also played a significant role in shaping how we approach development. Recently, we decided to move part of our pipeline logic that involved generating a YAML document to a dedicated web service deployed internally on the cluster. The main idea for the service was straightforward: listen for HTTP requests, perform some computation, and return the result. However, the ideal architecture for this service turned out to be less obvious. The specifics of the primary computation, which mostly involves dependency resolution and generation of the workflow DAG, required that we run Spack in operating system environments pre-built for this purpose. We did not want to reproduce these environments on top of a base image with a web server as these environment images were quite large and took a long time to build. However, neither was creating entirely new versions of these environment images just to add a web server, an appealing approach.
The challenge facing us was, fundamentally, the question of how to maintain separation of concerns when working with containerized applications. On this matter, Kubernetes takes a novel approach. Unlike other container orchestration platforms, Kubernetes makes a strong distinction between an application and the (possibly many) containers backing it and facilitates multi-container configurations with a feature-rich set of mechanisms for inter-container communication and data sharing. This combination of highly decoupled containers and strong data sharing features transformed the way we think about containers: They do not have to be feature-complete packages stuffed with everything needed to run (as is the case for many of the most popular images on Dockerhub); they can be smaller, more focused components that might not even do anything useful on their own, but are designed to run alongside other containers in various combinations.
In developing this internal service, we came to fully embrace this approach, effectively separating concerns along container boundaries, and taking advantage of Kubernetes capabilities to assemble them into logical applications. For example, we developed a delegating web server, which would merely accept requests, add them to a queue, and simply wait until a response is provided (presumably, from another container). With this component, it was very easy to run the main Spack computation in its own container and share the result with the container running the web server. Being so decoupled, the web component is also highly reusable, giving us a tool we can now use to wrap any computation on Kubernetes with a web service à la AWS Lambda. Using this same approach, we were able to further extend the service with additional features, such as caching results that were difficult or expensive to compute, without needing to make any modifications to the core service components. We think this approach represents a compelling paradigm shift in containers, where most new development can focus entirely on business logic, and the more “standard” features, like serving web traffic and maintaining a cache, can be available as prepackaged “add on” containers that can be included in an application simply by adding them to its ensemble.
Concluding Remarks
In summary, Kubernetes provides powerful automation and scaling capabilities to address the unique challenges in creating a custom-build pipeline for our Spack collaborators. Its novel approach to container orchestration and feature-rich, data-sharing mechanisms also make it an ideal platform for developing service-oriented applications. The pipeline is undergoing its final stages of testing and review, and we are all very excited to begin the transition to production. With Kubernetes as our platform, we have the confidence we need to make this transition, and the preparation to face any operational and development challenges that may await.
We are thankful to the Department of Energy (DOE) Exascale Computing Project (ECP) and Spack projects for funding this effort.