PHASTA + ParaView Catalyst: In Situ CFD Analysis at 256K MPI processes on BG/Q Mira

One of the things I really love about working on open-source projects is seeing where people take the things I’ve worked on. The latest example of this that just blew me away was with a CFD code called PHASTA, led by Ken Jansen at UC Boulder. Short for Parallel Hierarchic Adaptive Stabilized Transient Analysis, six years ago PHASTA was one of the first codes that ParaView Catalyst was prototyped with. Fast forward to a couple of months ago and I hear that Michel Rasquin, one of Ken Jansen’s postdoctoral researchers that’s now at Argonne National Laboratory, piloted remotely a PHASTA simulation instrumented with Catalyst on 256K MPI processes of the Argonne’s Mira system, an IBM BlueGene/Q. The Argonne Leaderships Computing Facility (ALCF) presented this live demonstration at the National User Facility Organization (NUFO) Annual Meeting in Washington, DC. This just blew me away (FYI: you can find the details of their latest CFD configurations along with a strong scaling analysis of PHASTA in their paper available from this link: http://www.computer.org/csdl/mags/cs/2014/06/mcs2014060013-abs.html). I won’t go into the full details of their setup but some of the Catalyst details of their runs include:
- They used a full edition of ParaView Catalyst Version 4.1 that was built static and cross-compiled
- They used an unstructured grid with 1.3 billion elements.
- The pipeline consisted of an isosurface of Q criterion and an isosurface of a quantity that gives a point’s distance to a wall. It is usually called wall distance and is useful for turbulent flow modeling.
- Generated 1920×1200 png images showing the Q criterion isosurface pseudo-colored by velocity magnitude and the wall distance isosurface colored grey.
- They estimated that the run-time overhead was roughly 40% for using Catalyst.
- They calculated that using Catalyst introduced roughly a 200 MB per MPI process memory overhead. This meant that they were only able to run with 2 of the 4 BG/Q hardware threads per core due to memory constraints.
- Some of the Python settings include
- Set PYTHONHOME to the target ParaView build directory so 256K processes did not try to search the entire file system for Python dependencies
- Set PYTHONDONTWRITEBYTECODE to a positive value so that 256K processes did not try to write to a single .pyc file.
- Did not statically link Python dependencies.
Some images generated from the run are shown below and movies are available at https://vimeo.com/120504264 and https://vimeo.com/120504265.
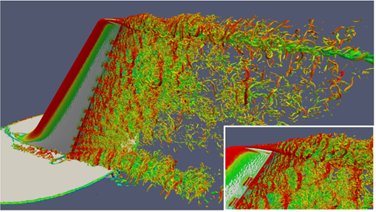
As I mentioned above, the runs were done using the full edition of ParaView Catalyst from ParaView 4.1. Since that time, significant improvements have been made to ParaView Catalyst that would have made the runs even more efficient. The first improvement was for handling the Python script. Since ParaView 4.2, process 0 reads the main Catalyst Python script and broadcasts it out to the other process. Each process then runs the script in the linked-in Python interpreter. This saves on file IO in two ways. First by having only a single process read the file and second by not having each file trying to write a .pyc file to disk (they did that by setting PYTHONDONTWRITEBYTECODE to a positive value to get the same effect). The other improvement is that there is now also a rendering edition of Catalyst. This reduces the Catalyst library memory overhead by roughly 50%. You can look at the paper by Nathan Fabian, et.al. for more information on this.
So in summary: wow, someone ran a Catalyst enabled simulation with 256K MPI processes and if they were to do it with the newly released ParaView 4.3, it would be even faster and easier than before.