Ongoing VTK / ParaView Performance Improvements

Over the last few years, significant performance improvements have been introduced into VTK and ParaView. Some of these have been dramatic – for example, when isocontouring linear unstructured grids speedups greater than 400x have been measured. In this post, we provide a high-level overview of how we achieved these gains and some numerical comparisons on a selection of the more important data visualization algorithms.
Before diving into the technical details, it should be noted that this effort has been a community effort (checking the git logs makes this plainly evident). Since VTK and ParaView are open source software systems, Kitware’s collaborators, community members, and customers – both commercial and governmental – have contributed guidance, feedback, and support for this work. Kitware remains committed to an open source business model, enabling its customers and collaborators to avoid vendor lock-in, reap the benefits of open technologies, and readily adapt and integrate this software into their own workflows and systems.
Approaches to Performance
Several, combined approaches were used to accelerate many VTK algorithms (or filters). While past efforts have addressed rendering performance improvements [1], GPU accelerator performance
through VTK-m [2], and even web deployment via VTK.js [3], this blog focuses on high-performance C++ components implemented on threaded CPUs in the VTK toolkit and deployed via the ParaView application. The performance gains we realized were not due to any one technology, rather the methodical development and combination of several emerging capabilities as described in the following.
- Infrastructure. Recent blogs have described ways to utilize templated code, dispatch execution based on data type, and efficiently access VTK data arrays [4]. In addition, algorithm accelerator structures such as point and cell locators have been parallel threaded, significantly speeding up common geometric search queries such as finding the closest point or searching for the cell containing a point. Finally, the construction of topological information, such as cell links (which enable fast queries such as what cells use a particular point, or face neighbors to a 3D cell), has been threaded. Even changes to the C++ standard have been important. In several cases, VTK now uses std::atomic to control threaded read/write operations.
- Specialization. When the VTK project began over 25 years ago, it was initially conceived as a prototyping, collaboration, and teaching tool. As a result, algorithms were implemented in a very general fashion, with performance being a secondary priority. However, with massive increases in data size and the widespread deployment of VTK and ParaView in mission-critical workflows, the need for improved performance has grown. As a result, what were once general data filters have been rewritten to target specific types of data, and/or common workflows. Such algorithmic specialization takes advantage of particular data organizational patterns to achieve significant performance gains. For example, it’s much faster to find the neighboring cells to a point in a volume than in a general unstructured grid.
- Threading. An abstract layer for CPU-based threading was introduced into VTK in 2013 as vtkSMPTools [5]. This extremely simple, yet surprisingly powerful abstraction enables VTK to use threading libraries such as OpenMP or Intel’s TBB. A key feature provided by the vtkSMPTools utility functions is the vtkSMPTools::For() parallel for loop, including support for thread pools and load balancing (if using TBB). In fact, this method is so simple it can be easily dropped into C++ lambda functions, and readily replace routine data processing loops.
- Invention. Sometimes the largest performance gains are realized by inventing a new algorithm to replace an older one. Many visualization data algorithms were first designed in the days when serial processing was the norm. However, with cheap computing cycles (e.g. multiple cores) now readily available from mobile to desktop systems, critical serial algorithms processing large data are being reexamined with an eye towards parallel implementations. A good example of this is the classic Marching Cubes algorithm – probably the most widely used visualization algorithm. As typically implemented, there are many performance inefficiencies, such as multiple processing visits to each vertex and edge and when merging duplicate points, the parallel bottleneck of point merging. As a result, we invented the Flying Edges algorithm [6], designed from the ground up for parallel execution. As far as we know, it is the fastest known single-pass isosurfacing algorithm, easily surpassing Marching Cubes with well over an order of magnitude performance gain (depending on the number of processing threads available).
Some Representative Performance Numbers
Table 1 below shows some performance numbers related to vtkUnstructuredGrids. It compares older versions of VTK and ParaView (PV version 5.4) with the current version (at the time of this writing PV version 5.9). These numbers speed-up factors and are by no means a definitive statement of the performance that all users will see, as the vagaries of OS, compiler, hardware, data, and filter options will produce different results. However, these numbers provide good ballpark estimates of expected performance increases. They were measured on a 2-year old desktop computer with 20 cores and 64 GByte of memory, running the Ubuntu 20.04 OS using the standard compiler (g++ 10.2.0) producing release-level code with TBB enabled as the threading engine. The numbers are normalized to the v5.4 execution times, or against competing generalized algorithms, so they directly express performance gain factors. Two datasets are used for testing: synthetic data with ~133 million tetrahedral cells; and a commercial customer-provided ~509 million cell unstructured grid dataset. Note that some of these filters have not yet been fully integrated into ParaView. Typically this is due to concerns of backward compatibility or deployment schedule (see Availability in the table).
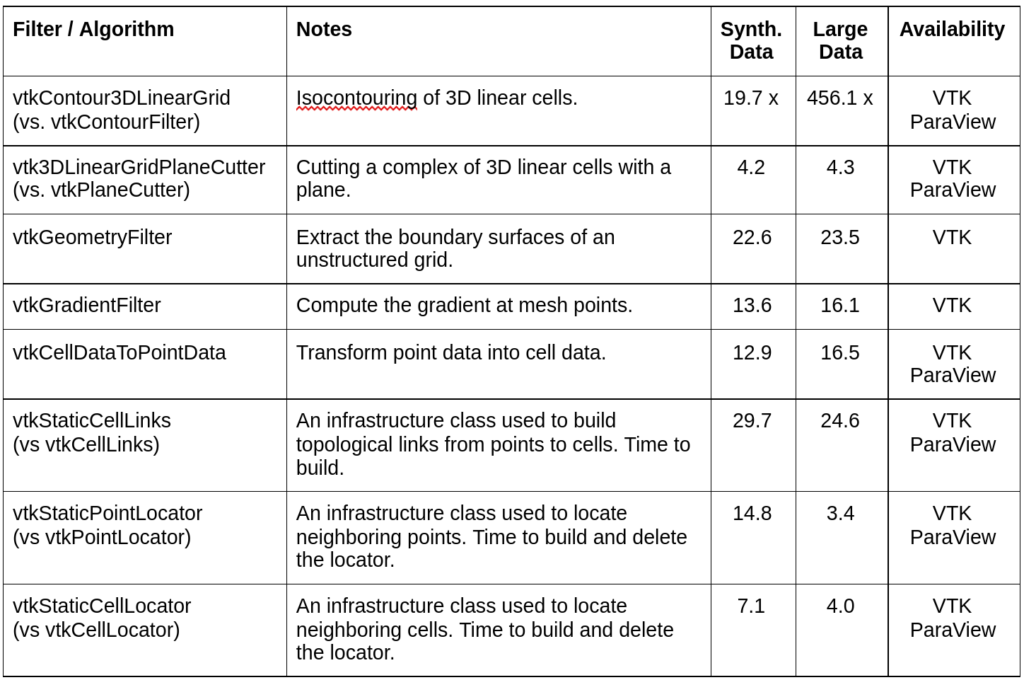
Table 2 is a selection of some additional performance-enhanced filters. Again, these are measured on the same system described previously, with data appropriate to what is expected by the filter.
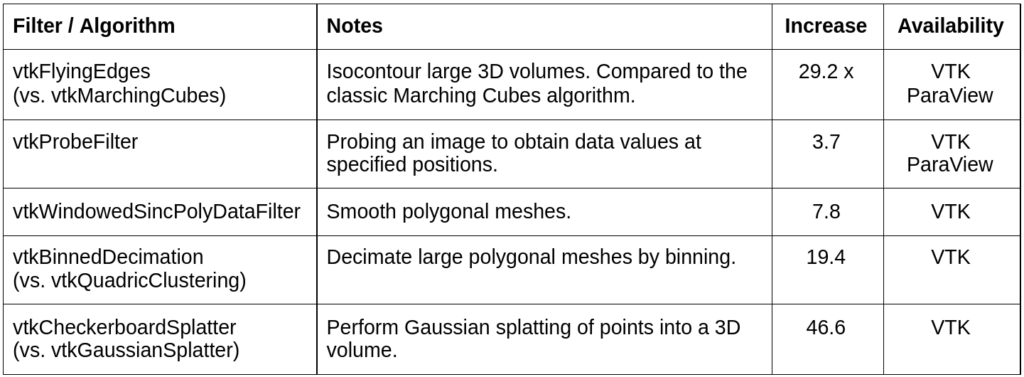
These tables list just a small sample of the filters accelerated over the past few years, many more have been indirectly accelerated through the use of infrastructure classes like vtkStaticCellLinks, vtkStaticPointLocator, and vtkStaticCellLocator; or modifications to vtkThreadedImageAlgorithm (thanks David Gobbi!) which impact a number of imaging algorithms.
Some of the performance improvements are quite surprising. For example, the new filter to isocontour 3D linear unstructured grids (vtkContour3DLinearGrid) leverages all four of the approaches described previously to obtain >400x speed improvements in one benchmark. By rewriting the algorithm to use the new templated class vtkStaticEdgeLocatorTemplate (instead of vtkPointLocator), the impact of extreme dynamic range in element size (due to a boundary layer in the data) on the point merging process is greatly reduced. Also, we’ve been delighted by the performance of vtkFlyingEdges – even though vtkMarchingCubes has been the de facto standard isocontouring algorithm since the late 1980s. By rewriting the algorithm for parallelism, greatly reducing the number of data access and operations on cell vertices and edges, and completely eliminating the point merging (parallel) bottleneck, greater than an order of magnitude speed improvements have been realized. Finally, some filters like vtkCellDataToPointData were initially written in a very general manner with several bells and whistles controlling how cell data was averaged onto connected points. It turns out that a very common workflow suffered significantly from the general approach. By coding a fast path for this workflow, huge performance gains were realized.
Conclusion
As evidenced in the table above, VTK and ParaView have seen dramatic performance improvements over the past few years. We, along with the VTKand ParaView open source communities, customers, and collaborators, will continue to identify and rectify performance bottlenecks, inventing new algorithms when necessary. Our goal is not only to provide the many benefits of open source software, but to ensure it delivers performance second to none. If you are interested in helping out, we welcome your feedback, funding, and other support.
Acknowledgements
We would especially like to recognize the National Institutes of Health for sponsoring a portion of this work under the grant NIH R01EB014955, “Accelerating Community-Driven Medical Innovation with VTK.”
Documentation
Parallel Processing with VTK’s SMP Framework Documentation
References
[1] K. Martin. Rendering Engine Improvements in VTK. https://blog.kitware.com/rendering-engine-improvements-in-vtk.
[2] VTK-m. https://m.vtk.org/index.php.
[3] VTK.js. https://kitware.github.io/vtk-js/index.html
[4] Dispatch and data arrays. https://www.paraview.org/Wiki/VTK/Tutorials/DataArrays.
[5] Schroeder, Philip, Geveci. Simple, Parallel Computing with vtkSMPTools. https://blog.kitware.com/simple-parallel-computing-with-vtksmptools-2/.
[6] Schroeder, Maynard, Geveci. Flying Edges: A High-Performance Scalable Isocontouring Algorithm. 5th IEEE Symposium on Large Data Analysis and Visualization. October 2015.
Great contributions! Thanks.