JupyterLab Trame Manager at Jülich Supercomputing Centre
This is a guest blog post from Jonathan Windgassen and Jens Henrik Göbbert, both developing the software stack at the Jülich Supercomputing Centre in Germany. They have agreed to share with us the integration of trame, jupyter lab and ParaView to ease the life of their scientists. As a bonus they include the code to reproduce their work on any supercomputer!
trame is a Python based framework developed by Kitware to easily create web applications for visual analytics. The trame architecture allows developers to access states, events, widgets, and user interfaces (UI) through Python, by hiding the complexity of web development. You can read more about it here.
The synergies between trame and JupyterLab make it a great combination for the development and usage of trame apps. For Data Scientists — likely users of trame apps — JupyterLab has become a popular tool for web-based interactive data analysis and a tool in their everyday work. To support this trend, the Jülich Supercomputing Centre (JSC) has been providing for some time now a JupyterHub called Jupyter-JSC for pure and direct browser-based access to its supercomputers as an easy access to HPC Resources.
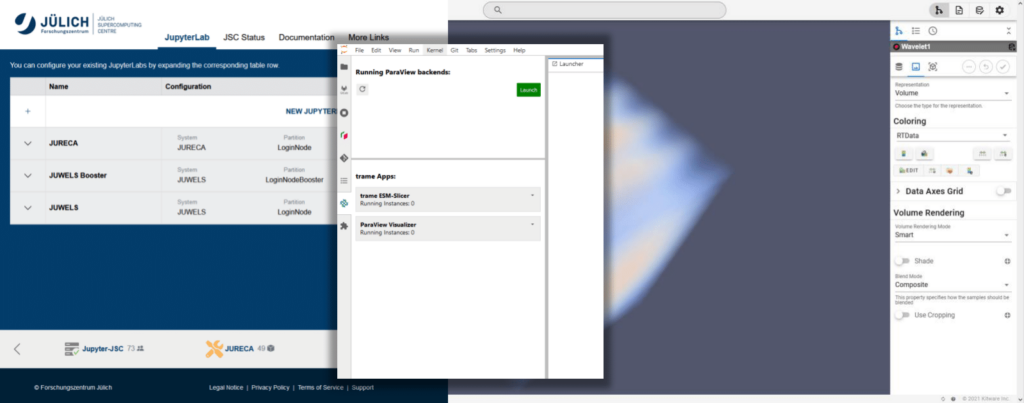
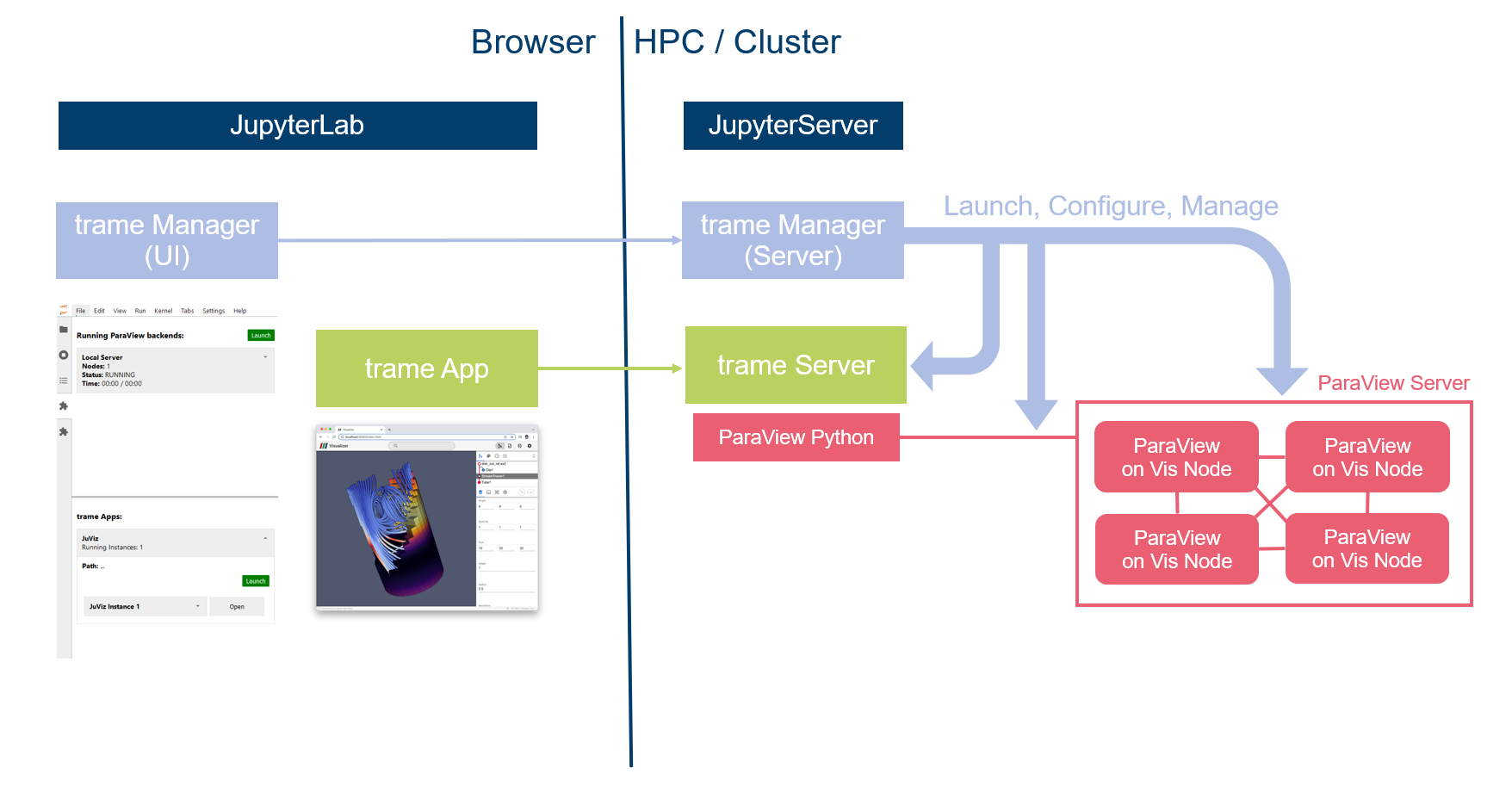
In the trend to move HPC applications and workflows to Jupyter-JSC, the combination of trame and JupyterLab has become an attractive combination. This motivated the development of the jupyterlab-trame-manager, where users can access trame apps directly in the browser, making the use of trame in HPC more visible, and easier to launch and manage. It also gives users access to ParaView’s remote visualization capabilities inside trame Apps, bridging HPC and cloud computing.
A showcase demonstrating the jupyterlab-trame-manager in action on the JupyterJSC Platform, can be seen here:
Concept
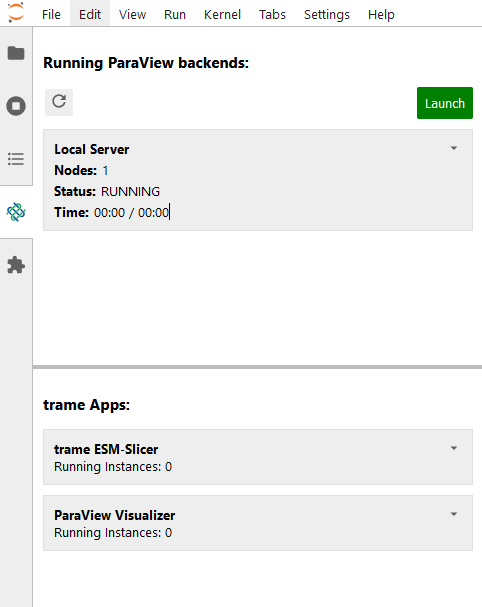
jupyterlab-trame-manager creates an additional side-panel in JupyterLab, which allows the management of ParaView Servers for remove visualization in the top section and trame Apps and their currently running instances in the lower one.
Custom trame apps can be made findable for jupyterlab-trame-manager via paths set in the environment variables. Each registered trame App itself contains a list of independently, decoupled running instances of this app, which can be separately managed.
These instances will run on the same server where the JupyterLab server is running, as a subprocess of the JupyterLab server. The frontend of the instance is tunneled through JupyterLab, allowing it to be accessed in the browser.
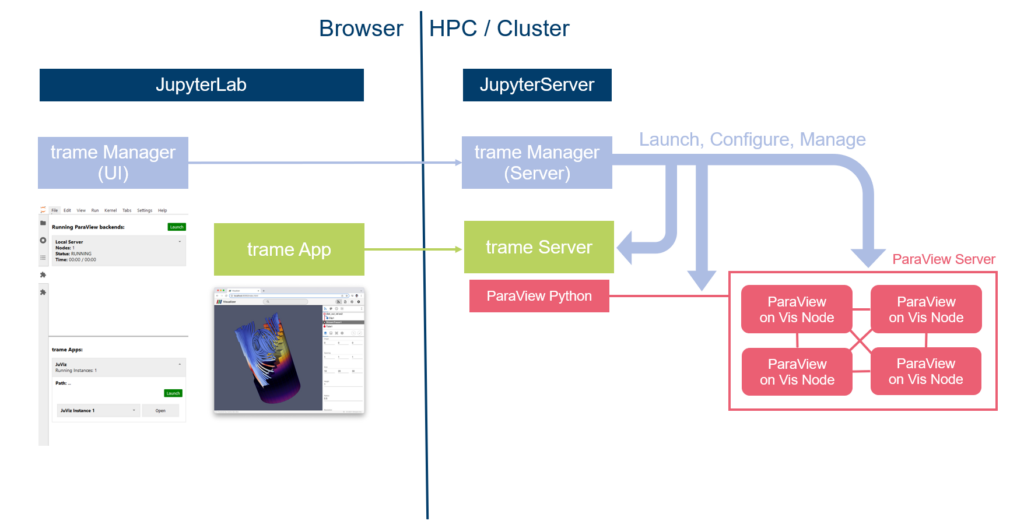
To utilize remote rendering in a trame app, each instance can be connected to a ParaView Server from the top Section. This will connect the instance to the ParaView Server, which can run on another node, i.e. a visualization node.
A schematic overview can be seen here:
Installation
The jupyterlab-trame-manager is platform-independent and capable of running on various architectures. It offers customizable, platform-specific configurations for launching apps and ParaView on specific HPC systems. Thus, the jupyterlab-trame-manager can be tried locally before installing it on a cluster.
To begin, install JupyterLab along with the jupyterlab-trame-manager extension using pip:
pip install jupyterlab jupyterlab-trame-manager
Before starting JupyterLab, specify what Configuration to use to the extension. For now, use the desktop Configuration, designed for the simple testing on a desktop:
export TRAME_MANAGER_CONFIGURATION=desktop
Once configured, start the JupyterLab Server:
jupyter lab
This should automatically open a new Tab in the browser and navigate to the JupyterLab interface.
Integrating a trame App
1) To register the trame application with the extension, you first need to place the app somewhere on the system where the JupyterLab will be running.
2) trame apps can be made findable via the paths stored in the JUPYTER_PATH environment variable, which is also used when installing a new Notebook Kernel. All directories in JUPYTER_PATH are searched for a trame directory (similar as they are searched for a kernel directory by Jupyter itself). If a subdirectory with a YAML file app.yml is found, jupyterlab-trame-manager will register a new trame app based on the configurations inside it.
By default, the JUPYTER_PATH environment variable will contain ~/.local/share/jupyter, where the app.yml can be placed at ~/.local/share/jupyter/trame/my-app/app.yml.
In the app.yml file, specify the following parameters for the application:
- name: The name to be shown in the UI. While the folder name is more of an internal representation of the app, this allows giving the application a nice, well-formatted name, shown in the UI.
- command: The launch command that will be executed to start the app. See below.
- working_directory (optional): From where the subcommand, which launches the app, is executed. Defaults to the location where the JupyterLab is executed.
In most cases, users would not only need to start their trame app, but also prepare the environment (loading modules, defining environment variables) before the startup. A single launch command is the easiest way to enable all of these preparations.
Info: To keep the JupyterLab environment as slim and free of potentially unnecessary dependencies, trame, ParaView and its dependencies should only be loaded during the launch command and should not be loaded before JupyterLab is started.
Some arguments of the launched app, like port and authentication key, are generated and need to be passed to the actual trame executable. These are contained inside a
INSTANCE_ARGSenvironment variable and must be appended to the python intepreter:python main.py --otherArgs $INSTANCE_ARGS
The final app.yml might look like this:
name: My trame App
working_directory: ~/.local/share/jupyter/trame/my-app/
command: |
module purge
module load Stages/2024
module load GCC ParaStationMPI
module load ParaView/5.12.0-RC2-EGL
module load trame/3.6.3-ParaView
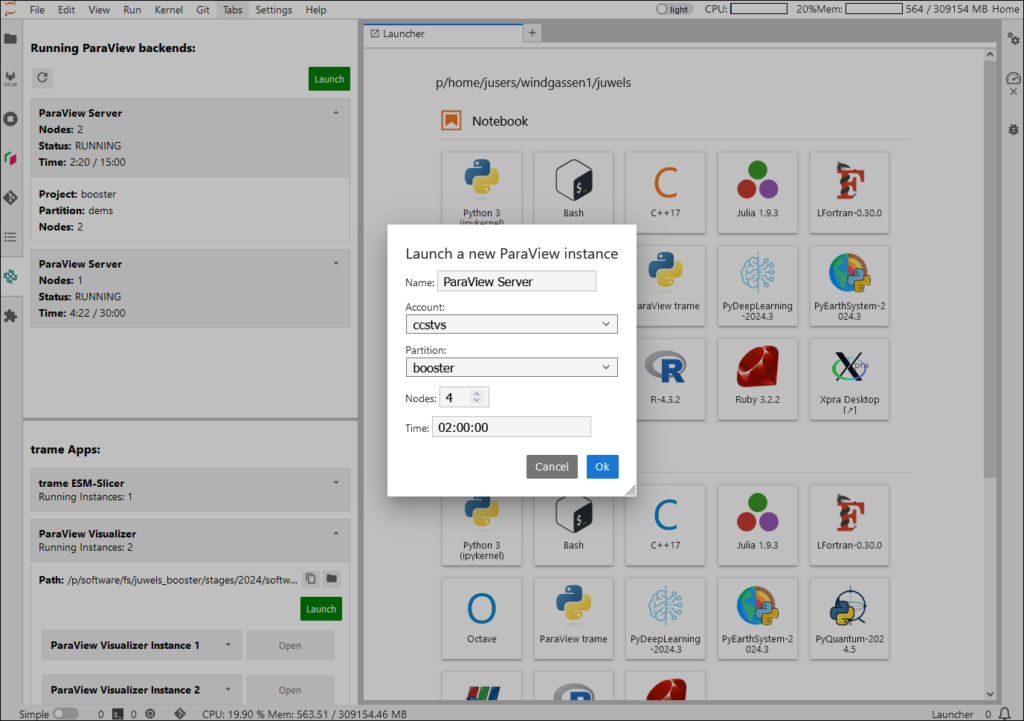
python __init__.py $INSTANCE_ARGS3) Start the trame app: Restart JupyterLab for jupyterlab-trame-manager to discover the app. It should then appear in the lower section of the sidebar. Expand the panel with the app and click on Launch. In the following Popup, give the instance a name and specify the data directory (used e.g. by the trame FileBrowser). After the app has started, click on Open, which will open the trame app in a new browser tab.
Using trame with Remote Rendering via a ParaView Server
When using VTK or ParaView in a trame app, some calculations can become quite compute intensive. For that reason, you might need to outsource these to a separate ParaView Server.
With the jupyterlab-trame-manager, this process can be automated, hence the list of ParaView Servers in the upper section of the extension.
Users can launch ParaView Servers, e.g., via SLURM, and then automatically initiate a connection between the trame app and the ParaView Server.
Info: With the
desktopConfiguration, however, the ParaView Server needs to be started manually. The extension is configured to always show a single Server onlocalhost:11111, which is the default Port the ParaView Server uses.
To try using the trame app with a ParaView Server, manually executepvserverin another terminal.
Warning: Not all trame Apps might directly work with ParaView’s Remote Rendering out of the box. trame apps might need to be updated to make this possible. We hope to make this process easier and more stable in the future.
After both the ParaView Server and the trame app are launched, a connection between them can be initialized by clicking on “Connect” on the panel for this trame instance and select one of the running ParaView instances to connect to:
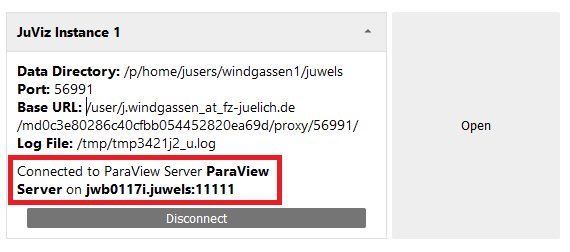
To allow the extension to initiate a connection between a trame app and a ParaView Server, the trame App must be prepared beforehand. To make this a breeze, we developed the trame-remote-control extension for trame.
It can easily be installed via pip: pip install trame-remote-control.
After that, it must be imported and initialized when the app starts. This will attach a REST-API Endpoint to the App, which the extension can use to initiate a connection to a ParaView Server. It can also be used to create a UI, which lets users connect and disconnect from ParaView Servers from within the application:
from trame.widgets import vuetify, remote_control
def main():
... # Other initialization code
remote_control.initialize(server)
... # Construct UI
with vuetify.VCol:
remote_control.create_panel(server)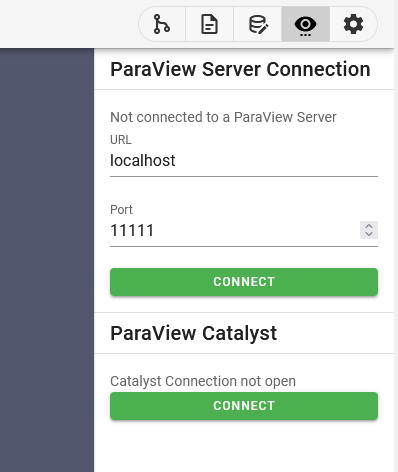
Utilizing HPC Resources
Now that the setup is running on a local desktop machine, it can be brought to HPC resources. The setup for this is almost identical to the desktop version, with the only difference being the Configuration specified.
The jupyterlab-trame-manager, by default, currently only contains configurations for desktop and the HPC Systems at the JSC, which can serve as inspiration for other systems. We are happy to merge new configurations directly into the repository, but they can, of course, also just be added to the local install.
Additionally, it might be desirable to use a software build framework to install the extension. At the JSC, we use EasyBuild. The easybuild file for installing the extension, as well as configuring it correctly, can be found here.
Outlook
While the current setup runs stably for most use cases, we still want to further improve and extend the functionality of the jupyterlab-trame-manager.
One prominent problem is the link between a running trame instance and the Jupyter Server. At the moment, trame instances are spawned as a subprocess of the Jupyter Server, linking the runtime of the two processes.
Instead, we plan to use Unicore in the future, which we currently also use on our HPC machines to spawn the JupyterLab itself.
As previously mentioned, we also want to improve the stability when using remote rendering with a ParaView Server.
Furthermore, we originally also planned to give the extension the ability to control in-transit visualization between the ParaView Server and a running Simulation on the Cluster.
This would allow users to easily contruct a full visualization pipeline, running from the simulation over a ParaView Server on some visualization nodes into the browser.
This work has been published as a poster at the ISC-HPC 2024 conference.
Thank you for your interest in reading this article. If you have any questions or ideas, feel free to contact Jonathan via email or reach out directly to Kitware for support.
Contributions and suggestions are always welcome!