Introducing KWCoco

KWCoco is Kitware’s COCO format and Python module that builds on the popular MS-COCO format introduced in the 2014 paper Microsoft COCO: Common Objects in Context and is supported by the pycocotools Python module. The MS-COCO format was designed to manage the large-scale (>200K) single-image MS-COCO dataset with bounding box, polygon, pixel-mask, and keypoint annotations with class labels. While this works well for a large number of vision problems, it is limited to still-image datasets – particularly natural image datasets. As a result, we are motivated to extend the format to express a larger number of vision tasks, while retaining the simplicity and efficiency that makes the MS-COCO format appealing.
The KWCoco format is backward compatible with MS-COCO, but adds capabilities such as supporting videos (time-series of images), multi-spectral images, large images, and linking annotations between images. These extensions support the remote sensing domain (i.e. satellite images / geospatial data) but also apply to other tasks such as video event detection/classification. The format is designed to be extensible and allows users to encode other information relevant to their problem.
This blog post is a high-level overview of the KWCoco data format and the associated Python package and API. We discuss these questions:
- What is KWCoco?
- What does KWCoco do well?
- What is the KWCoco roadmap?
What is KWCoco?
KWCoco is several things. A data manifest, an interchange format, and a Python module.
A “.kwcoco” file is a computer-vision data manifest. It is a file (e.g. a JSON file) that indexes assets (e.g. image data) on disk. It also stores annotation information about the data and metadata about itself.
KWCoco is an interchange format for computer vision datasets that is made to be read in and written out by programs. It can be used as an input to a training algorithm, an inference algorithm, or as output of a prediction algorithm (predicted rasters — i.e. heatmaps — can be written as new assets, and predicted vector-geometry can be written as new annotations). In practice, most inputs and outputs are read / written as compressed JSON files (e.g. with the `kwcoco.zip` extension), but other formats like uncompressed JSON, SQLite, and Postgres are available. It is easy to serialize and manage with version control like DVC.
KWCoco is also a Python module that defines a schema and provides tools for interacting with data conforming to that schema. The schema is effectively just a set of tables.
It’s important to be familiar with the objects in these tables and their relationships to use KWCoco. Figure 1 illustrates these tables and their relationships.
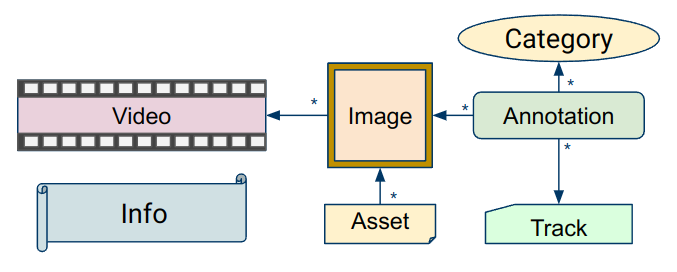 |
Each table stores a list of objects. A brief overview of each of these objects is as follows:
- Info – Stores unstructured metadata.
- Video – An ordered sequence of images. Note: videos in kwcoco are stored as images in frames. Support for video containers (e.g. mp4 with x265) is currently an open issue.
- Image – One or more raster assets on disk.
- Asset – A file on disk that stores data.
- Annotation – A true or predicted box/polygon / etc.
- Category – Stores the name of a category and optionally points to a parent category.
- Track – An ordered sequence of annotations in a video.
Like the original MS-COCO format, the dataset has a top-level list of all images, categories, and annotations. Each annotation points to the image and category it belongs to. An additional “info” table contains arbitrary metadata that can be used for application-specific tasks.
Unlike the MS-COCO format, KWCoco has new “Video”, “Asset”, and “Track” tables. The Video table keeps a small record for each video, and the images that belong to that video point to it and keep track of their frame number of timestamp. Similarly, tracks represent a group of annotations — typically within a single video — and each annotation points to the track it belongs to. Lastly, there is a concept of an “asset”. For most natural image problems this table is not needed, but in the case where an image corresponds to multiple files (e.g. different color channels are split across different files, each image consists of a stereo pair of images, or if there are RGB / depth-paired images), then each asset represents a physical file on disk, and points at a “conceptual image” to which it belongs.
Assets that belong to an image can store a transform that aligns the assets in “image view,” and likewise, images store a transform from “image view” to “video view,” where all images in a video sequence are aligned. An example of this is illustrated in Figure 2. See the docs for more info on KWCoco views.
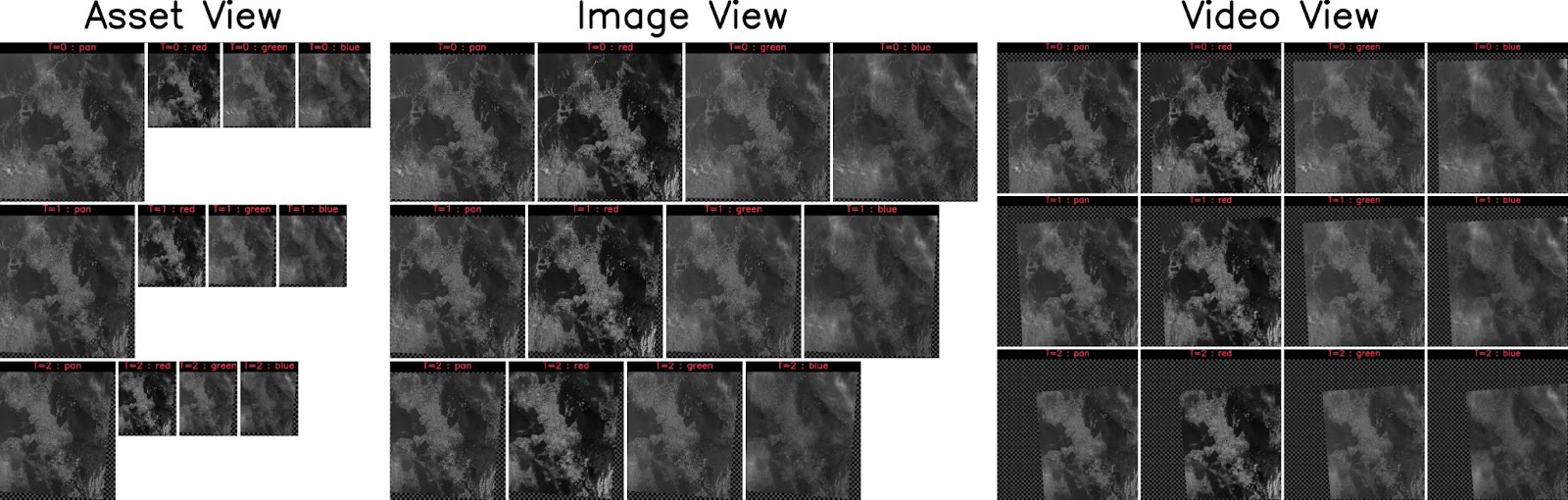 |
What Does KWCoco Do Well?
To interact with the KWCoco format, we’ve built the KWCoco Python module. By abstracting that interaction behind an API, a developer can write code that handles generic “KWCoco data” and minimizes assumptions about the dataset. An application that uses KWCoco will be able to swap in/out different datasets.
Compatibility: KWCoco is compatible with the original pycocotools implementation, and it also supports COCOvariants accepted by mmlab tools (e.g. mmdetection / mmsegmentation). It comes with CLI tools and methods to conform to formats by inferring information (e.g. image width / height) as well as validate the data schema.
Toydata: To help developers write dataset-agnostic code, the KWCoco module provides a “toydata” utility, which is able to generate simple images with various properties depending on the target domain. If you are a developer, this means you can write tests for your application that don’t rely on a (potentially proprietary) dataset existing on disk. You can use the toydata API to request a dataset of a specific size and with different attributes in the test itself. An example of the simple RGB image-only toydata is shown in Figure 3.
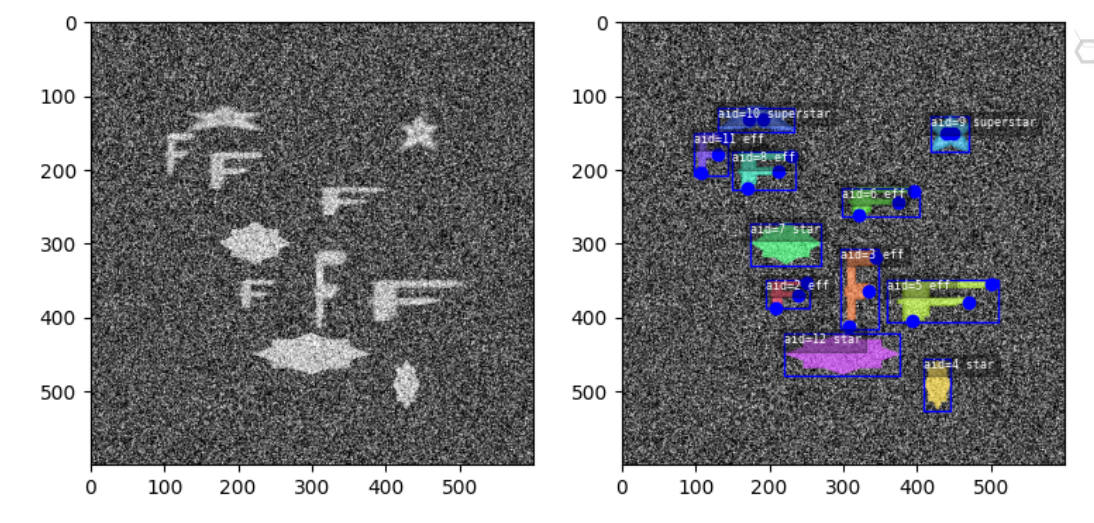 |
CLI: KWCoco has a scriptconfig-powered command line interface (CLI), which provides features like rich formatting, auto-complete, and a consistent API for invoking tools from Python or the shell. Notable command line tools include subset/union for combining/splitting apart datasets, move/reroot for managing paths and assets, stats/info for introspecting summary information, and validate/conform for checking and ensuring required fields exist. The top-level CLI help is shown in Figure 4.
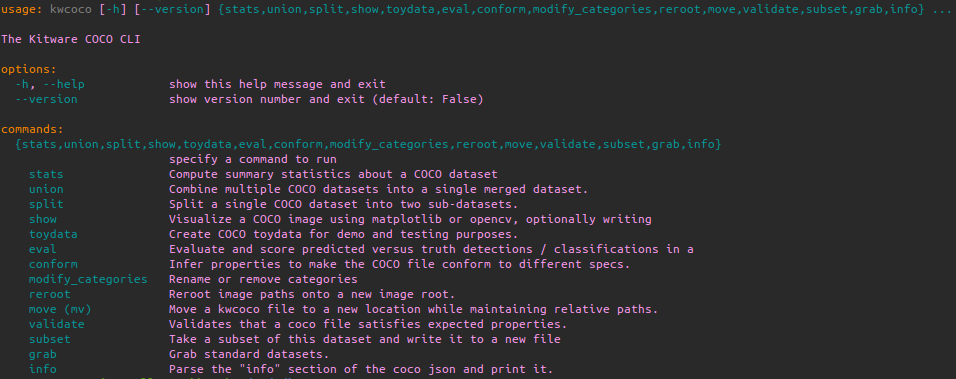 |
Evaluation: KWCoco has built-in detection metrics. Semantic segmentation metrics are implemented in geowatch and need to be ported. Tracking metrics need to be implemented.
Fast Sampling: By leveraging delayed-image and ndsampler, KWCoco can load data very quickly (often in-situ for formats like COG). Using GDAL we can handle large images.
Annotations: First-class annotation types are bounding boxes, polygon segmentations (holes allowed), and keypoints. Efficient data structures for handling these objects are provided by kwimage. Categories also have a built-in helper class, CategoryTree, which is useful for passing to networks. (We highly recommend passing your categories to torch models rather than hard-coding them.)
Backends: Various components of a KWCoco-powered system allow for switching between different backends. A KWCoco file can be written or read from a JSON file, a zipped JSON file, an SQLite file, or a Postgres database. Similarly, kwimage.imread (which powers delayed-image) has different IO backends it can use, such as cv2, ITK, or GDAL. These backends allow engineers to make informed choices to adapt and optimize to different environments. By default, KWCoco and related tools default to “reasonable-choice” backends, depending on what software is available on the system.
Content Identifiable Data: KWCoco files are designed to be hashed; that is, there is a method for computing a content-based identifier (also referred to as a hash-id), which is only recomputed if the file changes. This allows the user to cache any expensive preprocessing (perhaps with ubelt.Cacher) based on this hash-id. If the hash-id changes, then you know the underlying data has changed; otherwise, you can reuse existing results. These hash-ids are available for the entire file as well as individual tables, allowing for granular automatic cache invalidation. This technique enables the building of large automated systems on top of KWCoco.
Supporting Libraries: KWCoco has integrations with several other (currently Kitware) libraries.
NDsampler can detect if images are in a read-optimized format, and if requested it will precompute a more efficient cache (in COG format) that it can sample from. Figure 5 illustrates the speed benefit of using ndsampler and delayed-image to sample small subwindows from larger images.
 |
The GeoWATCH package consumes KWCoco files and uses them as the primary data interchange between vision pipeline processing steps. This package also defines a geospatial extension to KWCoco, which is important for handling remote sensing tasks.
What is the KWCoco Roadmap?
A major goal of KWCoco is to provide a versatile, user-friendly format for encoding vision data relevant to specific domains, without being limited to any one field.. This requires expanding the tables to support more domains. This also means improving existing code: faster and easier access to this data benefits downstream vision systems. There are many directions that KWCoco could take in the future. Specific development will be driven by the motivations of internal and external contributors. Potential directions include:
- Incorporating more modalities and data formats, like directly referencing video and audio assets rather than just images. Careful design is needed to integrate these new asset types efficiently.
- Improving internal efficiency – for example, using keyframes instead of per-frame annotations for tracks, and reworking the current combined image/asset table into separate tables.
- Increasing integration with external tools like DIVE, LabelMe, CVAT, labelstudio, torchgeo, etc.
- Adding functionality to enable researchers and developers to more easily gain standardized insights from their datasets. Possibilities include support for Well-Known Text (WKT) segmentation format, better reroot functionality, optimizing the SQLAlchemy API, per-image JSON files, and more.
In addition to improvements, there is also technical debt that must be addressed. This includes a reworking of tracks to use “key-frames”, a refactor of the internal asset table, and a track-id refactor. The gitlab issue tracker contains more information on open problems.
Conclusion
KWCoco is a mature and featureful package that builds on well-known standards. It extends MS-COCO, adding support for videos, tracks, and multi-spectral imagery. Data is easy to access with its efficient Python API and command line tools. It supports small or large datasets with its zipped JSON and SQLAlchemy backends.
Considering all these advantages, we’re confident in recommending KWCoco as a solution for managing your data. We hope this article inspires you to elevate your data management strategy and explore KWCoco’s offerings. With its growing adoption, KWCoco is set to redefine the standards for vision dataset interchange.