In Situ – In Transit Hybrid Analysis using Catalyst-ADIOS2 and ParaView
Last year, we introduced Catalyst-ADIOS2, a new Catalyst implementation capable to process simulation data on the fly on a dedicated visualization cluster. If you haven’t read it already, we suggest reading that initial blog post before diving into this one. Catalyst-ADIOS2 enables new in situ workflows (named “in transit”) that process simulation outputs without blocking the simulation itself. However, industrial usage of this technology has raised questions of scalability of data transfer between the simulation and visualization clusters: when the simulation output data is too large, it takes longer to send it to the visualization cluster than to process it directly! This blog post introduces an in situ – in transit hybrid approach addressing this concern using a new step of reduction before dataset transfer between clusters. Let’s dive in together!
Catalyst2: In situ workflows
To understand the motivation behind our hybrid approach, let’s go back to where it all started. In situ visualization comes from the idea of generating visualizations (“extracts”) from a long-running simulation after each time step has been computed, instead of waiting for the whole simulation to finish. This early feedback can be valuable for research scientists in a HPC context to analyze early results and ensure that the simulation is running as intended.
Recently, Catalyst 2.0.0 has been released. It provides a stable ABI to give simulations with in situ capabilities with only small code changes. Catalyst 2 uses the Conduit blueprint mesh protocol that defines the data structure to be sent to the Catalyst 2 implementation. One notable Catalyst 2 implementation is Catalyst-ParaView, which de-serializes Conduit meshes to VTK data structures and applies post-processing filters, executed in parallel, to generate extracted images or data files, using all the capabilities of ParaView’s Python API. This in situ processing happens synchronously on the simulation nodes after the simulation time step has finished and will be referred to as in line in the following.

Catalyst-ADIOS2 in transit
In the situation explained in the previous section, this Catalyst 2 in situ visualization pipeline needs to complete synchronously when triggered after each (or every N) time step. This constraint can significantly increase the total simulation runtime. To avoid this pitfall, a new Catalyst implementation was created, named Catalyst-ADIOS2. Instead of processing data in line with the simulation, Catalyst-ADIOS2 delegates the visualization pipeline execution to different computation nodes. This way, the simulation can resume once the data transfer is complete, and the visualization workload is executed asynchronously. This type of in situ analysis where the visualization work is performed on separate nodes is referred to as in transit, as opposed to in line. This is particularly useful for more complex visualization pipelines that can take advantage of GPU compute units for rendering, that may be available in nodes dedicated to visualization but not necessarily in simulation ones. From a technical perspective, this time, the visualization pipeline cannot simply use memory shared with the simulation running on the same machine, and needs to be sent through the network. This task is delegated to the ADIOS2 library, which is able to handle multiple distributed readers and writers. The drawback of this approach is that the output data is yet again transferred, defeating the original purpose of in-situ, which was relying on data already in memory, avoiding any costly copy.
Catalyst-ADIOS2 hybrid
In-transit processing introduced in the previous section helped accelerate workflows where a larger asynchronous visualization pipeline execution time compensated for synchronous data transfer times between both compute clusters. However, for workflows where data size is very large, as is it often the case in HPC, full data transfer over the network is simply not a faster option than doing all the visualization work in situ. I/O can quickly become the bottleneck when using in transit, which defeats the main idea of in situ by introducing the need for data movement. With this in mind, we had to find a way to reduce the amount of data transferred, in order to keep the transfer time low.
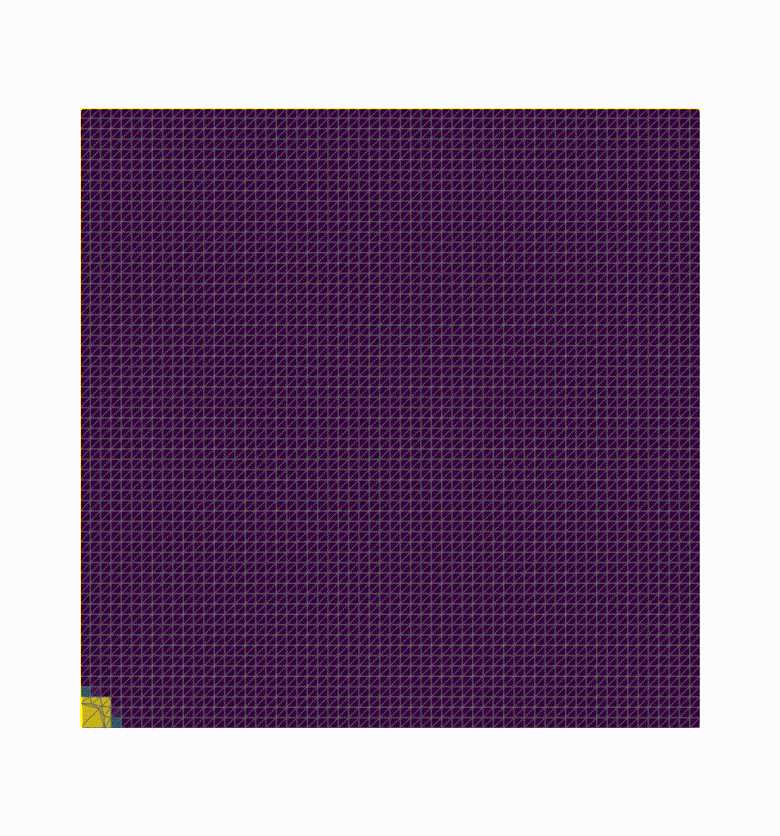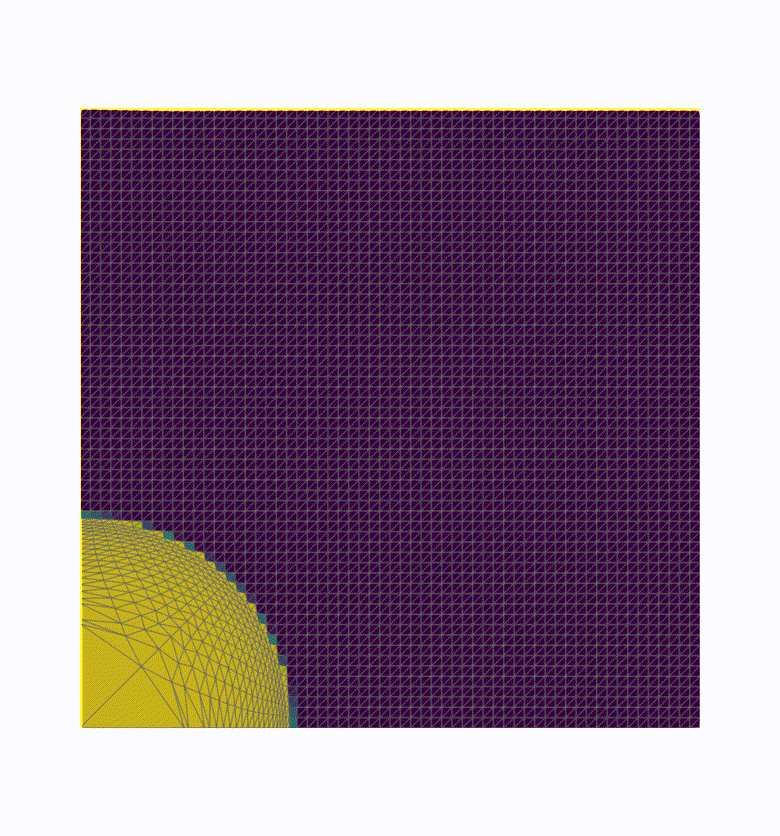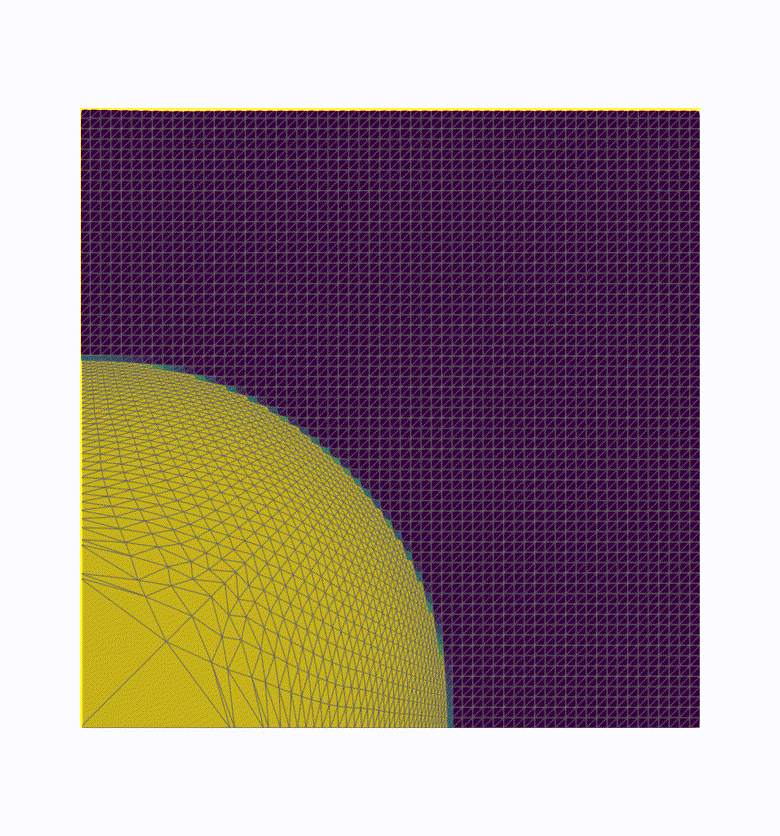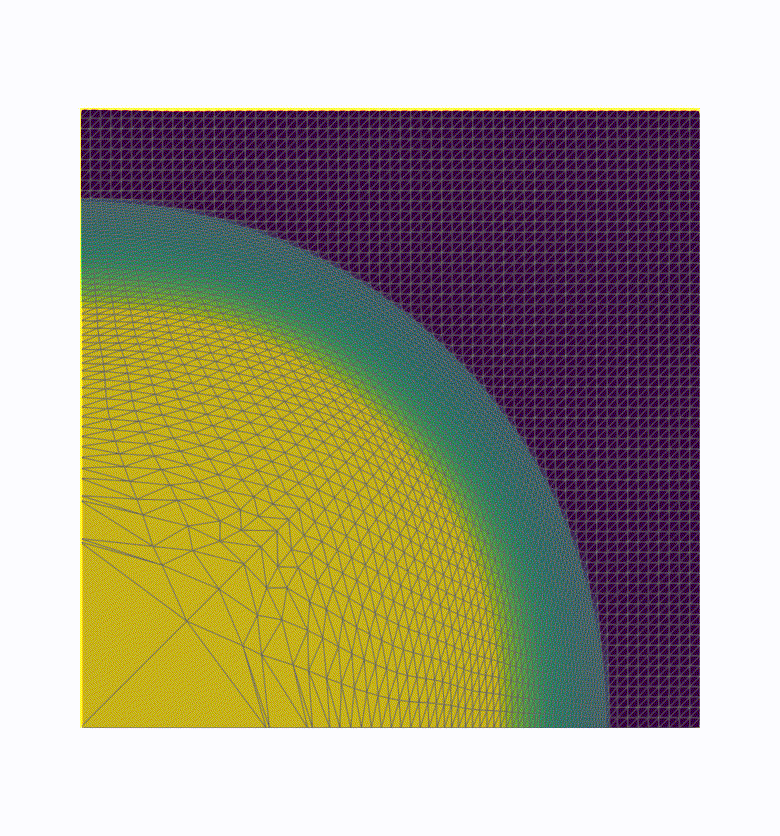
We realized that many visualization workflows only use part of the total data for rendering: common reduction methods involve clipping, surface extraction, slicing, down-sampling or selecting an area of interest. Our new “hybrid” approach involves a first reduction step done in line on the simulation nodes, before sending the data in transit to the visualization nodes for rendering. This way, we decrease the amount of data sent over the network, while still delegating most of the visualization work to the dedicated visualization nodes. We call it a “hybrid” between in line and in transit (first and second section), because we first reduce data in line on the computation nodes, and then send this reduced data just like we did in the in transit mode. See the timeline depicted figure 3 for a comprehensive view of our hybrid processing.

We have implemented this idea in the Catalyst-ADIOS2 implementation of Catalyst2. The user provides two ParaView Python scripts to the simulation which is instrumented using Catalyst. Catalyst-ADIOS2 runs the first script in line on the simulation nodes, applying reduction filters and “extracting” the reduced data, which is then sent to the Visualization nodes using ADIOS2. From there, the simulation resumes on the computation nodes, and the visualization nodes can do the rest of the visualization at the same time using the second ParaView-Python script, generating images of the reduced data for instance. You can view an example of this on the Catalyst-ADIOS2 repository.
Conclusion
These new developments create exciting new opportunities to apply in transit workflow on a larger scale. All the work described in this article is available publicly, under a permissive open-source license. There is always room for improvement and experimentation with this new technology, including AI-driven data reduction, which has yet to be tried.
This work led to a paper presented by Kitware at the 8th International Workshop on In Situ Visualization, held in conjunction with ISC High Performance 2024, in May 2024. You can read the pre-print version here.
You might rephrase the sentence “We recommend reading this first blog post before this one if you have not already”. Your meaning might be conveyed better as “If you haven’t read it already, we suggest reading that initial blog post before diving into this one.”