Improving CMake’s Runtime Performance
Last year, we made an effort to modernize code in the Visualization Toolkit (VTK). As part of this effort, we updated the CMake build system in VTK. We based the infrastructure on Modern CMake and CMake 3.3, in particular. This version of CMake is easily available from most Linux distributions; it adheres to usage requirements; and it provides C++11 detection for major vendors such as GCC, MSVC, Clang and Xcode.
The existing build system had developed a large amount of cruft, and it was causing CMake to perform tasks such as graph building and traversal. We presumed that reworking the build system would not only improve the readability and maintainability, but it would also improve the responsiveness of the software platform for users.
To our surprise, the performance of the new build system was consistent with the previous implementation. This prompted an investigation. Initially, we thought that the bottleneck came from the number of files that were created by VTK’s wrapping at generation time. With this in mind, we started to instrument CMake using perf. We visualized the results with a Flame Graph.

Based on the results, we realized that around 15 percent of CMake’s runtime was spent in cmMakefile::GetSource. Digging deeper, it became clear that cmSourceFile (a custom command) had no way to express that it represented a file whose absolute path was known. Therefore, CMake was unnecessarily performing expensive searching and extension matching. After refactoring cmSourceFile, it became possible to designate certain input, output and dependency information for the command as fully known. As a result, VTK’s workflow improved.

Additional efforts increased the performance of cmMakefile::GetSource by improving the source file lookup heuristics. Along with the refactor of cmSourceFile, the effort enhanced CMake’s performance over a wide range of use cases.
Example Use Case 1
Our first use case is a synthetic micro benchmark that constructs 10 custom commands. These commands are consumed by a custom target, which we call a single “block.” We ran the tests for this use case with the first release candidate of CMake 3.11 on Linux. On Windows, we discovered a performance regression, which we fixed in the third release candidate. As a result, we ran the tests with a commit that followed the second release candidate.
The table below displays the results. Please note that the number of loops was determined by the operating system, generator and blocks. In addition, note that “N/A” indicates a runtime that was too long to record.
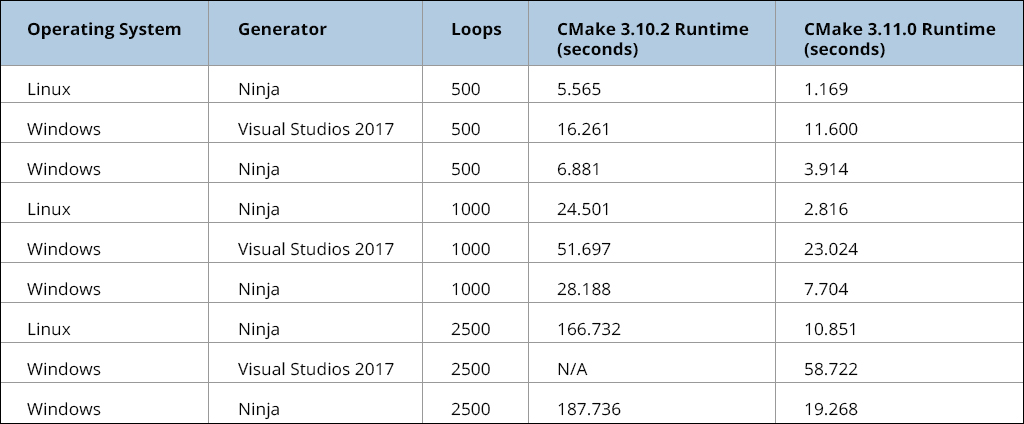
As the micro benchmark shows, before version 3.11, CMake’s performance did not scale linearly with the number of custom commands. For projects that use a heavy number of custom commands, this means that there will be a significant improvement in runtime come CMake 3.11.
Example Use Case 2
Our second benchmark looks at VTK with Python and Java wrapping enabled. These two options create numerous custom commands. We arrived at the benchmark using VTK’s master branch as of March 2, 2018.

Example Use Case 3
Our third benchmark looks at VTK’s new module system, which is still under development. The system leverages CMake’s target usage requirements.

The new module system enables all modules that are supported on the system. It differs from VTK’s current build system (Use Case 2), as the current build system builds a minimal subset of VTK by default. For this reason, the runtime durations are not comparable between Use Case 2 and Use Case 3.
Additional Improvements
While this blog focuses on the driving motivator behind a subset of the performance improvements, it would be a shame to not mention other improvements that will come with CMake 3.11:
- CMake’s AUTOMOC and AUTOUIC parsing and generation will be done in parallel.
- CTest’s parallel job execution will reduce runtime test latency overhead.
- Runtime will decrease for projects that have a significant number of import targets.
- Faster generate times will result from better source file lookup heuristics.
- Fewer heap allocations and string copies will improve configure and generate times.
We plan to make the final release of version 3.11 next week, so look for it on CMake’s download page.
I just noticed that my QMake builds are as much as 50% faster than CMake builds on Ubuntu 16.04. Maybe this will improve the situation..?
Would be interesting to see what percentage of time is due to cmake in a build of clang. Saw a benchmark this morning suggesting a fresh build spent almost 50% of its time in cmake and rest in the compile/link.
Be great to see how this improves with the changes you’ve made.
http://www.bitsnbites.eu/faster-c-builds/ found the Jan 2017 llvm blog post. 50% of build time noted near bottom of post…
Probably inaccurate these days….
One needs to cache also the CMake’s platform introspection for fast CI builds.
See https://github.com/cristianadam/cmake-checks-cache for how to achieve up to ~3x faster builds.
Why is Windows so much slower? Can that be fixed?
In general the MSVC generator is slower because msbuild start-up time is higher combined with having to generate multiple configurations ( Debug, Release, RelWithDebInfo ).
I personally use Visual Studio 2017’s CMake support which defaults to Ninja anyway. I compare that one to the CMake/Ninja on Linux which is till about 3x faster compared to Windows. Is Windows/NTFS that bad?