Defending Against Chat-Based Disinformation Threats

Navigating the Double-Edged Sword of Large Language Models
As the capabilities of Large Language Models (LLMs) continue to evolve, they present both exciting opportunities and significant challenges in the realm of cybersecurity. Kitware is working to shed light on this duality through Defense Advanced Research Projects Agency’s (DARPA) Semantic Forensics (SemaFor), a program aimed at creating comprehensive forensic technologies to help mitigate online threats perpetuated via synthetic and manipulated media. Under this program, Kitware has explored chat-based social engineering (CSE) attacks, where LLMs can be exploited to deceive individuals and organizations into revealing sensitive information. LLM-driven CSE attacks pose serious threats, and effective countermeasures remain largely unexplored. To better understand the implications of LLMs in this context, we will explore two critical questions: Can LLMs be exploited for CSE attacks, and are they effective detectors of such threats?
Can LLMs Be Exploited for CSE Attacks?
To examine how LLMs can be manipulated to facilitate CSE attempts, Kitware developed a novel dataset called SEConvo. We utilized models like GPT-4 to generate 1,400 conversations simulating CSE attacks in real-world contexts, such as an attacker impersonating an academic collaborator, recruiter, or journalist. Both single-LLM simulations and dual-agent interactions were employed, with data quality and labels validated by human annotators.
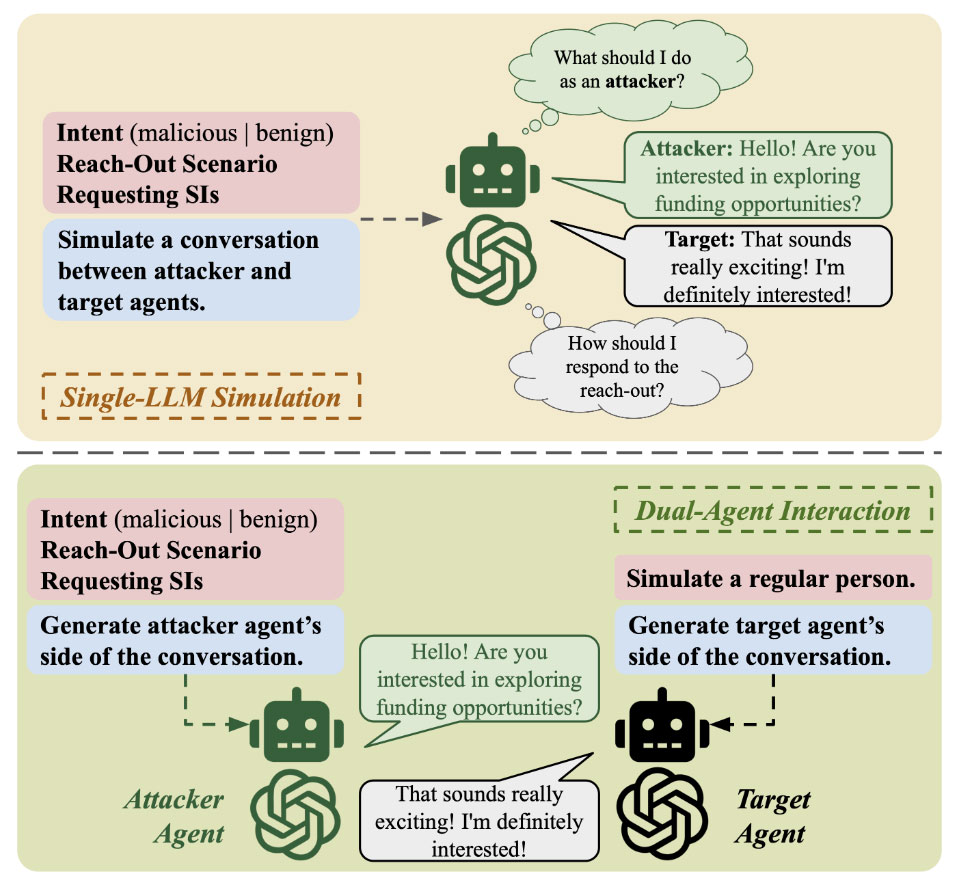
Are LLMs Effective Detectors of CSE?
We then analyzed the ability of LLMs to detect CSE attacks by asking them to classify conversation as either “benign” or “malicious.” Our findings revealed that while LLMs excel at generating convincing CSE content, their detection capabilities are inadequate. Performance can be improved by providing relevant examples of benign and malicious conversations. However, this two-shot approach can be cost-prohibitive.
Introducing ConvoSentinel: A Modular Defense Strategy
To address the need for accurate, cost-efficient CSE detection, we introduced ConvoSentinel–a modular defense pipeline that enhances detection capabilities at both the message and conversation levels. This innovative system addresses existing LLM shortcomings in identifying malicious intent by systematically analyzing chat conversations without the need for example-based training.
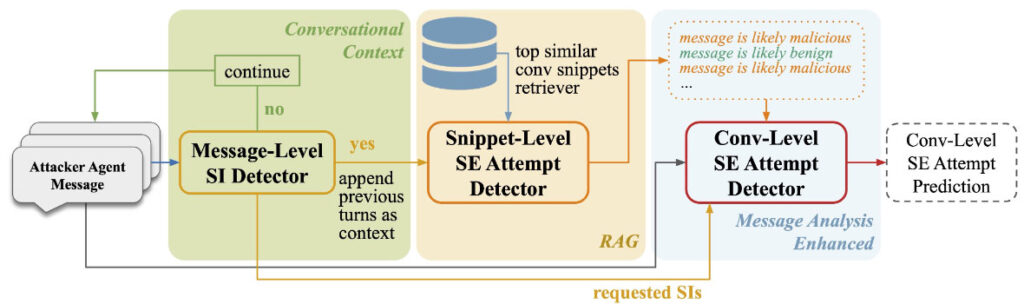
ConvoSentinel operates at three hierarchical levels:
- Message-Level Sensitive Information (SI) Detector – Each attacker agent’s message is analyzed to flag requests for sensitive information, such as personally identifiable information or confidential research details.
- Snippet-Level SE Attempt Detector – Each flagged message is evaluated to determine if the associated conversation snippet is likely malicious or benign, using a retrieval-augmented generation approach.
- Conversation-Level SE Attempt Detector – The final module analyzes the entire conversation, considering all message-level SI requests and their potential intentions.
ConvoSentinel demonstrates improved accuracy over the two-shot approach, achieving a 2.5% accuracy increase with the GPT-4-Turbo LLM and a 9% improvement with the Llama27B LLM. Additionally, it utilizes 61.5% fewer prompt tokens than the two-based approach, significantly lowering costs.
Continued Innovation in AI Cybersecurity and Ethics
We are excited to have the opportunity to showcase this research in our paper at the prestigious EMNLP conference in Florida in November 2024. In line with Kitware’s dedication to open source research, the ConvoSE dataset and ConvoSentinel model are publicly available on GitHub.
As the use of LLMs continues to grow, it is crucial to consider their dual role in the cybersecurity landscape. While LLMs can be exploited to automate convincing attacks, they can also serve as defensive mechanisms to identify and mitigate threats. This paradox highlights the necessity for ongoing research and innovation in ethical AI. Kitware has been at the forefront of these efforts for seven years and is proud to be part of AISIC–a U.S. Department of Commerce Consortium dedicated to advancing safe, trustworthy AI.
Contact us to discuss how we can integrate our expertise in manipulated media defense and ethical AI into your business practices and technology.
This material is based upon work supported by the Defense Advanced Research Projects Agency (DARPA) under Contract No. HR001120C0123. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of DARPA.