C++11 for-range support in VTK

Almost two years ago, the VTK development team made C++11 a hard dependency. The goal was to make VTK development less error-prone (e.g. adopting the override keyword) and more convenient (e.g. auto typing). As the codebase settles into the new world opened up by C++11, leveraging modern features in the project’s core will help VTK meet new developers’ expectations and ease integration with more recent projects, such as VTK-m.
C++11 for-range syntax
One of the most popular features introduced by C++11 is the for-range loop syntax. This language feature adds a new syntax for writing for loops that is safer and less cumbersome than what was available in C++03. Previously, there were two common approaches to processing all elements in a standard container: by index or by iterator:
std::vector<float> myVector = ...;
float sum = 0;
// Index:
for (size_t i = 0; i < myVector.size(); ++i)
{
sum += myVector[i];
}
// Iterator:
for (typename std::vector<float>::const_iterator it = myVector.begin();
it != myVector.end(); ++it)
{
sum += *it;
}
There are drawbacks to both. Index based iteration can introduce errors in more complex usecases, as the index operator ([] ) is not bounds-checked and a common error is to write past the end of an array, silently corrupting memory and possibly creating exploitable code paths. Iterator-based traversal is less likely to have this problem, as the begin and end of the range are more clearly marked, but it is cumbersome enough to write that many developers avoid using it. The introduction of auto and decltype helped simplify this, but it was still a lot of boilerplate typing and error-prone manual checking for the data’s end point.
The for-range syntax addresses these issues by introducing a syntax that is both succinct and safe, hiding the details of the loop inside of a : , where they’re guaranteed to be correctly used:
// for-range iteration:
for (float value : myVector)
{
sum += value;
}
This is equivalent to both of the earlier examples, but it easier to type, faster to read, and less error-prone. That about covers how things work in the standard library, but what about VTK?
vtkDataArray APIs
In VTK, data is stored in vtkDataArray s, and these have additional complications:
Tuple + Component Abstraction
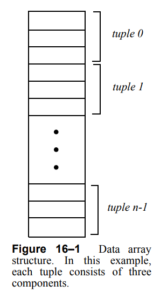
Unlike the std::vector above, a vtkDataArray is not a flat list of values, but rather an abstracted list of “tuples” made up of “components”. This complicates access patterns and leads to multiple APIs for interacting with the data. Values can be requested or modified using their tuple/component coordinates, or fetched into a local buffer one tuple at a time.
Typeless Base Class with Templated Implementations
Another key difference between the VTK and STL containers is that we know what sort of data the std::vector<float> holds: it contains float s. We know this because std::vector is directly templated with its value type.
VTK’s containers are more complicated. The vtkDataArray class is not templated; it may hold any type of data: float, int, char, etc, but the vtkDataArray API deals only in doubles, using virtual method calls and typecasts to fetch and convert the array’s data to a common type. This not only adds a significant performance hit to every array access, but also introduces errors in the case of 64-bit integers, which cannot be fully represented by the double data type.
To avoid the virtual call and typecast issues, the type-explicit subclasses of vtkDataArray may be used directly. These offer APIs that are better optimized and compiler-transparent, enabling performance improvements through inlining and auto-vectorization when appropriate.
Multiple Storage Backends
Until recently, these type-explicit subclasses were the familiar types vtkFloatArray, vtkUnsignedCharArray, etc, which inherit from the vtkAOSDataArrayTemplate class template. They all had the same array-of-structs (AOS) memory layout to represent tuples, and it was possible to obtain a raw pointer to their memory buffer to write optimized code. This worked well for a long time, but as VTK has increasingly been used in zero-copy in-situ contexts, the need to conform to other memory layouts efficiently became more and more important.
Today, VTK natively offers supports for struct-of-arrays (SOA) layouts, and custom layouts can be added efficiently using the vtkGenericDataArray interface. These extensions mean that raw pointer access is no longer a viable route for optimizing a vtkDataArray of unknown origin, such as a filter input, since we can no longer expect them to have an AOS memory layout, or even exist in-memory at all.
Iterating through vtkDataArrays
There are more than a few ways to process the elements in these data structures. Let’s take a look at how the use of these containers evolved, from the slower and less general methods, to the faster techniques that are generic across container types. We’ll look at the example of computing the magnitude of vec3’s and storing them in a separate single component array.
vtkDataArray API
This approach calls methods on a vtkDataArray object, which bounce to a virtual override and typecast the underlying data to double.
void mag3(vtkDataArray *vectors, vtkDataArray *magnitudes)
{
const vtkIdType numTuples = vectors->GetNumberOfTuples();
std::array<double, 3> tuple;
for (vtkIdType t = 0; t < numTuples; ++t)
{
vectors->GetTuple(t, tuple.data());
double mag = 0.;
for (double comp : tuple)
{
mag += comp * comp;
}
mag = std::sqrt(mag);
magnitudes->SetTuple(t, &mag);
}
}
Pros:
- Works for all vtkDataArray objects.
- Simple to write, easy to read.
Cons:
- Slow.
- Optimized versions would require additional implementation.
GetVoidPointer and vtkTemplateMacro
For a long time, this was the preferred way to write fast-path code in VTK. Before SOA and other variations of vtkDataArray, AOS memory layout could be assumed, and the raw memory buffer could be accessed via GetVoidPointer. The returned pointer could be cast to the appropriate type using vtkTemplateMacro and operated on directly. As shown below, things would get a bit messy when more than one array was needed, since the template macro only handled one type at a time.
template <typename VecType, typename MagType>
void mag3Helper(VecType *vecs, MagType *mags, vtkIdType numTuples)
{
for (vtkIdType t = 0; t < numTuples; ++t)
{
MagType mag = 0;
for (size_t i = 0; i < 3; ++i)
{
mag += static_cast<MagType>((*vecs) * (*vecs));
++vecs;
}
*mags = std::sqrt(mag);
++mags;
}
}
template <typename VecType>
void mag3Trampoline(VecType *vecs, vtkDataArray *mags, vtkIdType numTuples)
{
// Resolve mags data type:
switch (mags->GetDataType())
{
vtkTemplateMacro(
mag3Helper(vecs,
static_cast<VTK_TT*>(mags->GetVoidPointer(0)),
numTuples));
default:
// error...
}
}
void mag3(vtkDataArray *vecs, vtkDataArray *mags)
{
const vtkIdType numTuples = vecs->GetNumberOfTuples();
// Resolve vecs data type:
switch (vecs->GetDataType())
{
vtkTemplateMacro(
mag3Trampoline(static_cast<VTK_TT*>(vecs->GetVoidPointer(0)),
mags,
numTuples));
default:
// error...
}
}
Pros:
- Produces highly optimized code.
- Works with most AOS layout arrays (vtkBitArray is an odd duck…).
Cons:
- Either breaks or triggers a full in-memory copy when array is not AOS.
- Cumbersome and difficult to use.
- Hard to read.
- Error prone raw pointer handling.
- Quickly gets complicated when handling multiple arrays.
- Requires separate implementations to handle arrays not supported by vtkTemplateMacro.
- Produces significant code bloat as separate workers for all supported data types must be compiled. This is greatly exacerbated by working with multiple arrays, and the number of generated workers is [numDataTypes] ^ [numArrays].
Type-Explicit-Subclass APIs
This approach uses methods on type-explicit vtkDataArray subclasses. Here, we fallback to the vtkGenericDataArray interface to achieve an implementation that works for both AOS, SOA, and other layouts.
template <typename D1, typename T1, typename D2, typename T2>
void mag3(vtkGenericDataArrayTemplate<D1, T1> *vectors,
vtkGenericDataArrayTemplate<D2, T2> *magnitudes)
{
using VecType = T1;
using MagType = T2;
const vtkIdType numTuples = vectors->GetNumberOfTuples();
for (vtkIdType t = 0; t < numTuples; ++t)
{
MagType mag = 0;
for (int c = 0; c < 3; ++c)
{
VecType comp = vectors->GetTypedComponent(t, c);
mag += static_cast<MagType>(comp * comp);
}
mag = std::sqrt(mag);
magnitudes->SetTypedComponent(t, 0, mag);
}
}
Pros:
- Much faster. Memory accesses become inlined.
- No unnecessary typecasts.
- No virtual function calls.
- Works for most vtkDataArray subclasses (again ignoring vtkBitArray )
- Still readable.
Cons:
- Won’t work with vtkDataArray pointers, separate implementation needed.
- Won’t autovectorize, AOS stride is unknown to the optimizer.
- Readable, but verbose.
vtkDataArrayAccessor
The next advancement in vtkDataArray usage came in the form of the vtkDataArrayAccessor helper class. This utility switches between the slow-but-reliable vtkDataArray API and the faster type-explicit array APIs. Combined with the VTK_ASSUME macro to provide hints about array strides to the compiler, this could achieve performance equivalent to raw pointer access for type-explicit arrays, while using the same implementation for a fallback path when the array type is unknown.
Combined with the vtkArrayDispatch utilities, the code bloat problem is reduced by introducing forms of restricted dispatch — meaning that a fast-path could be compiled for commonly expected array types while falling back to the slower generic implementation otherwise. More information on these tools is available in this blog post.
struct Mag3Worker
{
template <typename VecArray, typename MagArray>
void operator()(VecArray *vecs, MagArray *mags)
{
// The Accessor types:
using VecAccess = vtkDataArrayAccessor<VecArray>;
using MagAccess = vtkDataArrayAccessor<MagArray>;
// The "APITypes"
// (explicit-type when possible, double for plain vtkDataArrays)
using VecType = typename VecAccess::APIType;
using MagType = typename MagAccess::APIType;
// Tell the compiler the tuple sizes to enable optimizations:
VTK_ASSUME(vecs->GetNumberOfComponents() == 3);
VTK_ASSUME(mags->GetNumberOfComponents() == 1);
const vtkIdType numTuples = vecs->GetNumberOfTuples();
VecAccess vecAccess{vecs};
MagAccess magAccess{mags};
for (vtkIdType t = 0; t < numTuples; ++t)
{
MagType mag = 0;
for (int c = 0; c < 3; ++c)
{
VecType comp = vecAccess.Get(t, c);
mag += static_cast<MagType>(comp * comp);
}
mag = std::sqrt(mag);
magAccess.Set(t, 0, mag);
}
}
};
void mag3(vtkDataArray *vecs, vtkDataArray *mags)
{
Mag3Worker worker;
// Create a dispatcher. We want to generate fast-paths for when
// vecs and mags both use doubles or floats, but fallback to a
// slow path for any other situation.
using Dispatcher =
vtkArrayDispatch::Dispatch2ByValueType<vtkArrayDispatch::Reals,
vtkArrayDispatch::Reals>;
// Generate optimized workers when mags/vecs are both float|double
if (!Dispatcher::Execute(vecs, mags, worker))
{
// Otherwise fallback to using the vtkDataArray API.
worker(vecs, mags);
}
}
Pros:
- Handles all types of vtkDataArray, including vtkBitArray, with a single implementation.
- Reduces code bloat by only generating unique fast paths for a restricted combination of arrays, falling back to a generic implementation otherwise.
- As efficient as raw-pointer access in the fast paths.
Cons:
- Very, very verbose. This code is readable, but there is a lot of it and it uses several advanced/unintuitive concepts.
- Lots of things to remember to get good performance…accessors, assumes, dispatch, etc.
Overall, this approach is great from a performance / code-size viewpoint, but not so much from a writeability / maintainability one.
C++11 for-range loops with vtk::DataArrayTupleRange
The worker code above can be cleaned up using the new vtk::DataArrayTupleRange and vtk::DataArrayValueRange helpers. These produce a proxy object that represents a range of tuples or flat AOS-indexed values, respectively. They make the worker code simpler by:
- Optimizing for tuple sizes known at compile time via a simple template parameter (no need for mystical VTK_ASSUME incantations).
- Transparently switching between optimized direct access or generic vtkDataArray access without the need to deal directly with vtkDataArrayAccessors.
- Implicitly iterating over the array range. By default the entire array is traversed, but the start/end points can be customized and are encapsulated in the range object.
- Enabling the use of STL algorithms to assist in computation.
The dispatch code is still needed and would be identical to before, but the worker is simplified to:
struct Mag3Worker
{
template <typename VecArray, typename MagArray>
void operator()(VecArray *vecs, MagArray *mags)
{
// Create range objects:
const auto vecRange = vtk::DataArrayTupleRange<3>(vecs);
auto magRange = vtk::DataArrayValueRange<1>(mags);
using VecType = typename decltype(vecRange)::ComponentType;
using MagType = typename decltype(magRange)::ComponentType;
auto magIter = magRange.begin();
for (const auto& vecTuple : vecRange)
{
MagType mag = 0;
for (const VecType comp : vecTuple)
{
mag += static_cast<MagType>(comp * comp);
}
*magIter++ = std::sqrt(mag);
}
}
};
Some observations:
- This code works whether the input arrays are type-explicit or not, and will produce highly optimizable instructions when possible.
- The component sizes are optionally passed as a template parameter during the creation of the ranges. This is not necessary if the component size is unknown, but using this feature when possible will produce better optimized code.
- vtk::DataArrayTupleRange<3>(array) is faster than vtk::DataArrayTupleRange(array), but both have identical usage.
- A tuple range (vtk::DataArrayTupleRange) is used for the vectors, since we want to process these tuple-by-tuple. A value range (vtk::DataArrayValueRange) is used for the magnitudes to simplify the code.
- For a single-component array, the tuple abstraction is burdensome and the value iterators are more intuitive.
- Even when using a ValueRange, it is worthwhile to specify a compile-time component size when possible, since it doesn’t have to equal 1.
- The range construction methods can also create restricted ranges by passing start / end points as function arguments:
- vtk::DataArrayTupleRange(array, startTuple, endTuple) and vtk::DataArrayValueRange(array, startValue, endValue) will iterate over the indicated portions of the full array’s data.
- The range objects define several typedefs that are useful in generic programming contexts:
- Range::ArrayType – The array type with which the range has been instantiated.
- Range::ComponentType – The API type of the array (double for vtkDataArray or the actual data type otherwise).
- The various iterators and iterables define the STL-standard types as necessary:
- value_type, size_type, difference_type, iterator, const_iterator, reference, const_reference, pointer, iterator_category, etc.
The Range objects extend the lifetime of the array they contain. They hold a reference to the array, so as long as a Range object exists, the data it describes is guaranteed to be valid.This is no longer true – the ranges no longer modify the array’s reference count to make it cheaper to construct short-lived ranges.
STL Compatibility
These iterators are fully usable by the STL algorithms. For instance, the magnitude computation could be implemented using the std::transform algorithm like so:
struct Mag3Worker
{
template <typename VecArray, typename MagArray>
void operator()(VecArray *vecs, MagArray *mags)
{
// Create range objects:
const auto vecRange = vtk::DataArrayTupleRange<3>(vecs);
auto magRange = vtk::DataArrayValueRange<1>(mags);
using VecTuple = typename decltype(vecRange)::const_reference;
using MagType = typename decltype(magRange)::ComponentType;
// Per-tuple magnitude functor for std::transform:
auto computeMag = [](const VecTuple& tuple) -> MagType
{
MagType mag = 0;
for (const auto& comp : tuple)
{
mag += static_cast<MagType>(comp * comp);
}
return std::sqrt(mag);
};
std::transform(vecRange.cbegin(),
vecRange.cend(),
magRange.begin(),
computeMag);
}
};
Debugging
A useful feature of the ranges and iterators is optional safety checking. By enabling VTK_DEBUG_RANGE_ITERATORS in VTK’s CMake options and compiling in Debug mode, additional compile and runtime checks are enabled that ensure the iterators are used properly. The resulting code will run much slower than normal, but common usage errors such as mixing iterators from different arrays, dereferencing invalid iterators, or iterating out-of-bounds will be caught.
Benchmarks
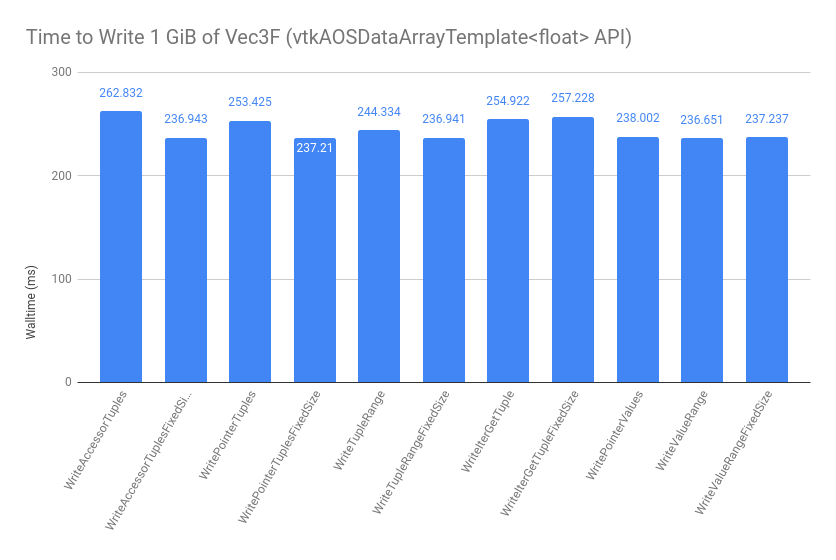
The methods of array access described above have been benchmarked using this script. When iterating over an AOS-backed vtkDataArray handle, various methods of array access are shown below:
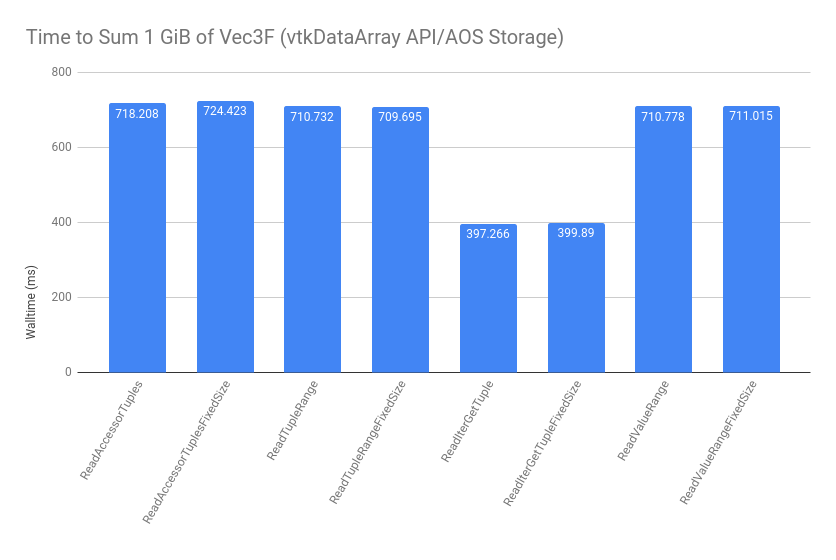
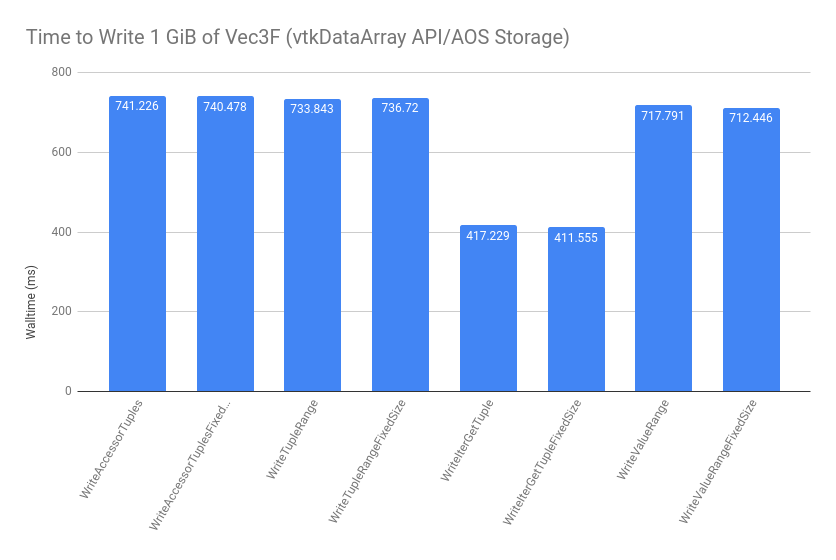
The implementations for these benchmarks are shown in the above link, but they correspond with the techniques covered in this post. The FixedSize variants inform the optimizer at compile time what the tuple size is. We see that the TupleRange and ValueRange tests perform as well as the Accessor tests, which is the target for accessing one component of the array at a time. The IterGetTuple tests use the following technique to extract each tuple iterator’s data into a contiguous local array:
static constexpr vtk::ComponentIdType NumComps = ...;
const auto range = vtk::DataArrayTupleRange<NumComps>(array);
using ComponentType = typename decltype(range)::ComponentType;
using TupleRefType = typename decltype(range)::TupleReferenceType;
std::array<ComponentType, NumComps> data;
for (TupleRefType tuple: range)
{
tuple.GetTuple(data.data());
// Do work with data
tuple.SetTuple(data.data());
}
These are much faster for the vtkDataArray case because it only requires one virtual call per tuple, rather than one per component.
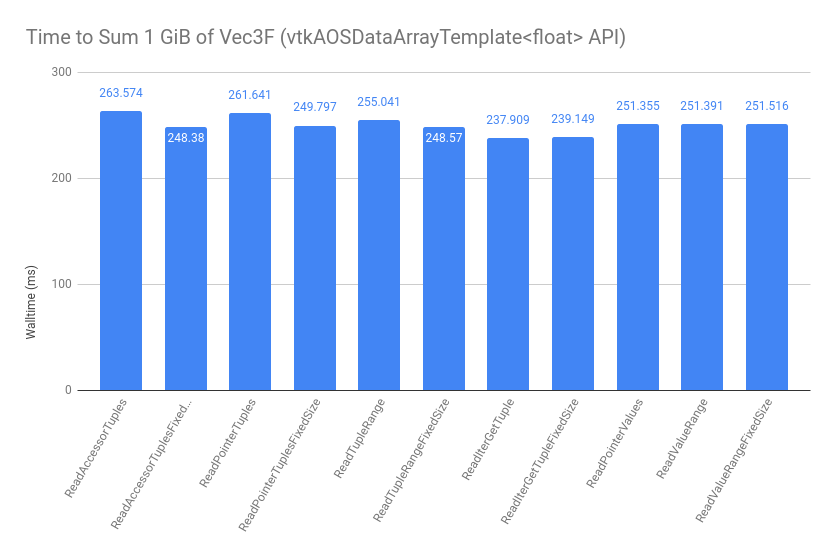
Looking at the type-explicit AOS interfaces, the performance is even across the board, indicating that the ranges and iterators are transparent to the compiler and they perform at the same level as the raw pointer code:
Summary and Caveats
These range and iterator utilities provide a new mechanism for interacting with vtkDataArrays safely, efficiently, and with a high degree of flexibility and compatibility. They take advantage of known tuple sizes to produce optimized instructions, and can be easily restricted to a subset of an array’s data. Iteration can be performed using C++11 for-range syntax, and can step through data tuple-by-tuple and component-by-component (TupleRange), or by walking the array in an AOS pattern (ValueRange). The range proxies and iterators are compatible with STL conventions, and can be used seamlessly with the STL algorithms.
The one major feature missing from the new iterators is that operator[] is not implemented, making random access a bit more tedious in certain cases. This is due to how references interact with the auto keyword. There’s not a straightforward way to implement this without breaking reference/value semantics or leaving dangling references, so the operator is disabled. Certain specializations may still allow it to be used, but enabling VTK_DEBUG_RANGE_ITERATORS in cmake will catch these usages and emit errors. This is no longer true; indexing an iterator will now work as expected, but auto/auto& may not work as expected, and the value/reference type aliases on the range objects (or std::iterator_traits) should be used instead. This follows the pattern for reference proxies used by the STL, e.g. std::vector<bool>.
It’s a bit early to talk about best practices, but it does appear that using the GetTuple method with the tuple iterators is, in general, the fastest way to use the tuple ranges. The performance is comparable to the other methods for type-explicit arrays, but significantly faster for the slow-path since the number of virtual calls is reduced.
Along with the ranges and iterators, a new vtkDataArrayMeta.h header file is added, which contains metaprogramming helpers for working with vtkDataArrays. It introduces a vtk:: namespace, and populates it with:
- typedefs for array index types (vtk::ValueIdType, vtk::TupleIdType, and vtk::ComponentIdType).
- helpers for static assertions and SFINAE checks.
- A class to strip pointers (including VTK’s smart pointers) from an arbitrary type.
- A container that transparently switches between a compile-time constant and a runtime tuple size to simplify optimizing code.
The addition of these features will hopefully provide a fresh, modern feel to the VTK toolkit, and simplify the process of writing highly performant code in generic contexts. Do you have ideas for other ways to leverage new C++11 features in the VTK codebase? Feel free to leave your thoughts in the comments below!