Achieving Interactivity with a Point Cloud of 2 Billion Points in a Single Workstation
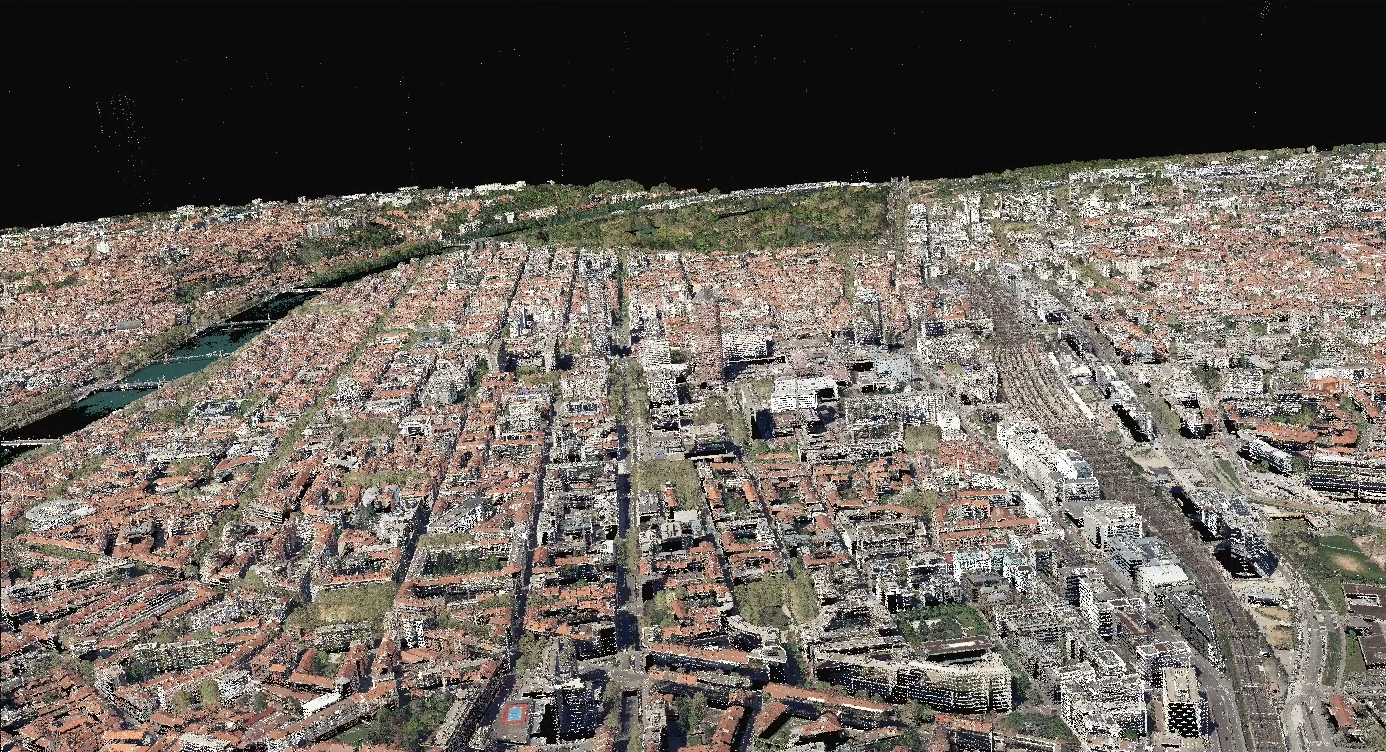
Point cloud of 2 billions of points from The Grand Lyon rendered by VTK with WebGPU
Recently, Kitware internal development made it possible to use a new type of shader in VTK with WebGPU: the Compute Shader. Already presented in a previous blog post, this modern rendering approach allows us to offload computations from the CPU to the GPU. It offers a wider range of rendering optimizations, such as occlusion culling, and algorithms like the point cloud rendering approach presented in this blog post which drastically outperforms the OpenGL integration of VTK in this case.
All of this work is available in VTK master under a new mapper, the vtkWebGPUPointCloudMapper. Note that there is a dedicated example to test it easily.
Overview of the algorithm
Traditional graphic APIs are capable of rasterizing point clouds, for example with GL_POINTS using OpenGL. This is how VTK currently proceeds with the OpenGL backend.
The recent work of Schütz and al.[SKW21] proposes to render points via compute shaders rather than the conventional rasterization-based pipeline. The idea is to “manually” rasterize the points in a compute shader and maintain a depth buffer and an image for the color of the processed points. The atomic operations method presented in this article has been implemented and partially adapted with the compute shaders API of VTK.
The method is simple and consists of:
- projecting each point on the screen with the camera projection matrix,
- storing the depth of the fragments in a depth buffer with atomicMin(),
- writing its color on the image if the point is closest to the camera (compared to all the points projected so far, i.e. the value of the depth buffer).
This paper presents some additional improvements in terms of performance and quality. Note that since these features depend on advanced extensions which lack support in WebGPU for most devices, they are not (yet) available in VTK’s main branch.
Benchmark
The benchmark described below has been measured on a machine equipped with an NVIDIA RTX A6000 (48GB of VRAM) + i9 12900KF under Ubuntu 22.04. Note that the rendering API used behind WebGPU is Vulkan.
To evaluate the performance of this implementation, we realized a benchmark which consists of recording the time spent to render a frame during a predefined animation (see Fig. 1) with a different number of points. The complete results can be found below in the table in Fig. 4. For each targeted number of points, the benchmark was run multiple times with datasets from 2 different databases: IGN and Grand Lyon.
Fig. 1 Animation used during this benchmark for a tile (~30 millions of points) from the Grand Lyon.
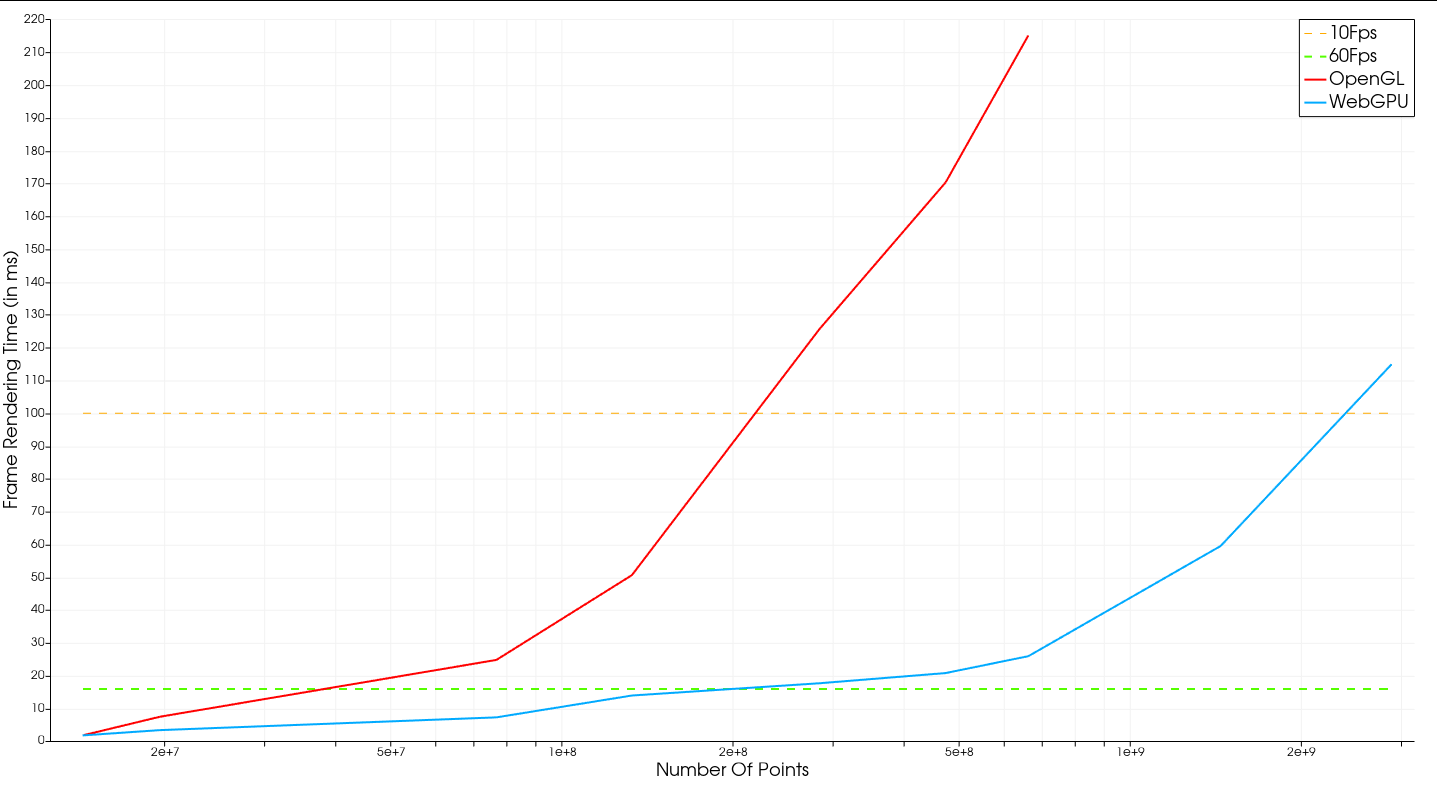
The result of this benchmark (see Fig. 2) shows how the new point cloud mapper with the WebGPU backend scales much better with massive point clouds. We can achieve interactivity with a point cloud of over 2 billions points where OpenGL could not render the point cloud when it goes beyond roughly 700 million of points on this hardware.
Although there is no significant speedup with datasets smaller than 15 million points, we can render a frame 2 to 10 times faster with respectively 20 to 700 million points. This result corresponds to what we expected from the article.
Note that we were not able to load a bigger point cloud with the OpenGL backend due to the VRAM capability of the machine used during this benchmark, but the scaling should follow the trend.
Fig. 2 Time comparison between OpenGL and WebGPU backend to render a frame, depending on the number of points. (lower is better)
Regarding VRAM consumptions, both OpenGL and WebGPU backend use a significant amount of memory, see Fig. 3, which slows the first rendering due to cpu to gpu transfer. However it is interesting to see that even without optimizing it with compression, WebGPU takes less space than OpenGL.
| Number Of Points | OpenGL (in Mib) | WebGPU (in Mib) |
| 15 000 000 | 330 | 290 |
| 75 000 000 | 1519 | 1243 |
| 285 000 000 | 5470 | 4420 |
| 525 000 000 | 8356 | 8107 |
| 1 100 000 000 | NaN | 17364 |
| 2 400 000 000 | NaN | 40010 |
Fig. 3 VRAM consumption in our OpenGL and WebGPU implementations with different sizes of point clouds. OpenGL couldn’t render point clouds with more than a billion points.
The complete result of this benchmark, regarding performance, can be found in the table below.
| Number of points | OpenGL (in ms) | WebGPU (in ms) |
| 15 000 000 | 1.83401 | 1.83376 |
| 20 000 000 | 7.52069 | 3.44625 |
| 75 000 000 | 24.8409 | 7.33633 |
| 150 000 000 | 50.688 | 11.9957 |
| 300 000 000 | 125.674 | 14.7319 |
| 475 000 000 | 170.387 | 19.8377 |
| 700 000 000 | 275.149 | 26.9844 |
| 1 400 000 000 | NaN | 59.5507 |
| 2 800 000 000 | NaN | 114.959 |
Fig. 4 Average frame rendering time for different sizes of point clouds with our OpenGL and WebGPU backends. OpenGL couldn’t render point clouds with more than a billion points.
Limitations
As this new mapper was focused on rendering performance, it still lacks some features compared to the OpenGL one which could definitely be integrated in the future. For example, for now the point cloud can only be rendered with a specific scalar array and a dedicated color map.
We should also take account of another important limitation related to the buffer size. With WebGPU, we cannot store more than 400 millions of points in a single VTK actor. If the dataset exceeds this limit, it needs to be split into multiple actors, like we did in the benchmark. It’s worth noting that we applied the same split in the OpenGL case to ensure that we have the same test conditions.
Conclusions
This new point cloud mapper is another great example of compute shaders’ usage, and how it can be implemented using WebGPU. It also opens new exciting perspectives regarding point cloud rendering: being far more efficient than its OpenGL counterpart, we can imagine leveraging the rendering time saving to render more complex scenes, and implement more advanced rendering techniques as shown in the paper.
The point cloud mapper could also be extended to support new rendering techniques like gaussian splatting, glyph representation and more. If you’re interested in testing or integrating it, or even implementing a new algorithm using the WebGPU integration, do not hesitate to reach us.
This work was funded by an internal effort at Kitware Europe.
The datasets used to create the video and to benchmark our integration of the new algorithm are under permissive license and came from 2 differents sources:
- An aerial database made in 2018 by the Grand Lyon : https://data.grandlyon.com/portail/fr/jeux-de-donnees/nuage-points-lidar-2018-metropole-lyon-format-laz/info
- Another lidar point cloud resource from IGN https://geoservices.ign.fr/lidarhd
If I were to serve out point cloud data via ParaView+Trame on a remote parallel cluster but viewed via Google Chrome which has WebGPU, will I still benefit from the above approach ?
Currently not, because ParaView couldn’t be use with WebGPU for now.
However, once Paraview supports WebGPU, it should definitely make the difference in your context.