A VTK pipeline primer (part 3)

In previous blogs (1, 2), I started discussing how the VTK pipeline functions. We covered the basics and how RequestInformation works. In this article, we will discover how RequestUpdateExtent and RequestData work. Once you have a good understanding of these 3 passes, you can develop all kinds of algorithms, ranging from very basic to sophisticated.
RequestUpdateExtent
This pass is where algorithms can make requests for the upstream pipeline to fulfill. Its name originates from the first use case for this pass: requesting a subset of logical extent from an image source (aka update extent). In the current VTK, this pass is used for requesting many other things including time steps, partitions (pieces), ghost levels etc. Let’s dig into an example. First let’s create a request key with the following.
requestKey = keys.MakeKey(keys.IntegerRequestKey, "a request", "my module")
Then let’s make a request using this key (at the end of the file):
f.UpdateInformation() outInfo = f.GetOutputInformation(0) outInfo.Set(requestKey, 0) f.PropagateUpdateExtent()
Let’s also change the filter and the source to print out the keys in the information objects during RequestUpdateExtent:
class MySource(VTKPythonAlgorithmBase):
def RequestUpdateExtent(self, request, inInfo, outInfo):
print "MySource RequestUpdateExtent:"
print outInfo.GetInformationObject(0)
return 1
class MyFilter(VTKPythonAlgorithmBase):
def RequestUpdateExtent(self, request, inInfo, outInfo):
print "MyFilter RequestUpdateExtent:"
print outInfo.GetInformationObject(0)
return 1
Now when we run our example, here is the output:
MyFilter RequestUpdateExtent: vtkInformation (0x7fae09e73650) ... a request: 0 MySource RequestUpdateExtent: vtkInformation (0x7fae09e732d0) ... a request: 0
So far, we let the pipeline simply copy upstream the a request key. However, it is sometimes necessary for a filter to modify a request value during the RequestUpdateExtent pass. For example, a filter may need a layer of ghost cells to produce piece-independent results and may add a ghost level to the request. Let’s change MyFilter’s RequestUpdateExtent to increment the value of a request.
class MyFilter(VTKPythonAlgorithmBase):
def RequestUpdateExtent(self, request, inInfo, outInfo):
print "MyFilter RequestUpdateExtent:"
print outInfo.GetInformationObject(0)
areq = outInfo.GetInformationObject(0).Get(requestKey)
inInfo[0].GetInformationObject(0).Set(requestKey, areq + 1)
return 1
Now the output will look as follows:
MyFilter RequestUpdateExtent: vtkInformation (0x7fae09e73650) ... a request: 0 MySource RequestUpdateExtent: vtkInformation (0x7fae09e732d0) ... a request: 1
Here is a graphical representation of what is going on.
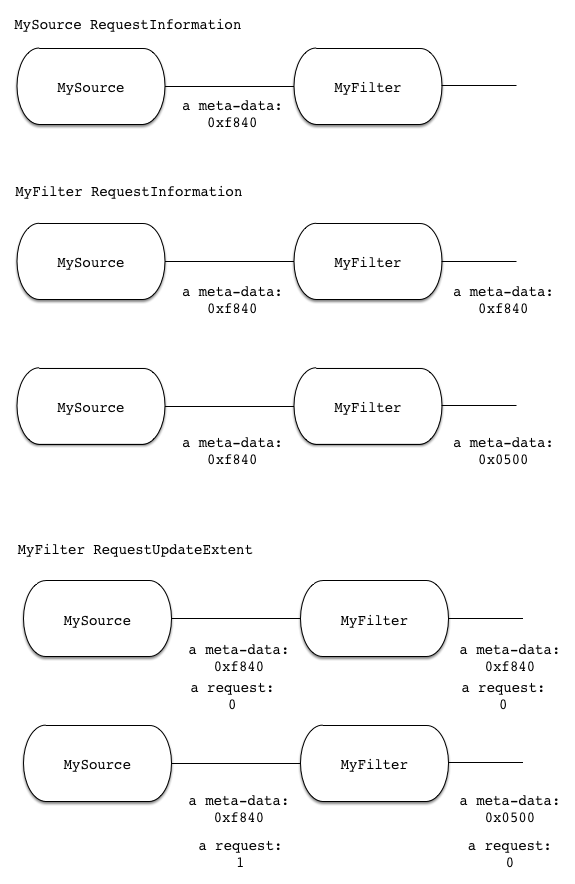
Simple huh? A few things to note:
- Certain keys are copied upstream by the pipeline automatically during RequestUpdateExtent. These include all keys of type vtkInformationIntegerRequestKey, UPDATE_EXTENT, UPDATE_NUMBER_OF_GHOST_LEVELS, UPDATE_PIECE_NUMBER etc.
- Any automatic copying happens before the algorithm’s RequestUpdateExtent is called so that it can overwrite anything done by the pipeline.
We are now done covering all of the meta-data passes. In summary:
- In RequestInformation, the source produces meta-data, the pipeline copies these values downstream by default and the filters modify the meta-data as it propagates downstream.
- In RequestUpdateExtent, the sink (or the user at the end of the pipeline) makes requests and as these values propagate upstream, filters modify them to fit their needs.
RequestData
Hopefully, this section is trivial to most readers. In RequestData, data, originally produced by sources, is transformed by filters as it propagates downstream. This is very similar to RequestInformation, the main difference is that “heavy” data is processed in RequestData as opposed to meta (light) data in RequestInformation.
In this pass, algorithms deal with the vtkDataObject.DATA_OBJECT() key, which is preset by the pipeline or the algorithm (more on this some other time). Let’s modify our example to do some work in RequestData:
class MySource(VTKPythonAlgorithmBase):
def RequestData(self, request, inInfo, outInfo):
print "MySource RequestData:"
outInfo0 = outInfo.GetInformationObject(0)
areq = outInfo0.Get(requestKey)
s = vtk.vtkSphereSource()
s.SetRadius(areq)
s.Update()
output = outInfo0.Get(vtk.vtkDataObject.DATA_OBJECT())
output.ShallowCopy(s.GetOutput())
print output
return 1
class MyFilter(VTKPythonAlgorithmBase):
def RequestData(self, request, inInfo, outInfo):
print "MyFilter RequestData:"
inInfo0 = inInfo[0].GetInformationObject(0)
outInfo0 = outInfo.GetInformationObject(0)
input = inInfo0.Get(vtk.vtkDataObject.DATA_OBJECT())
output = outInfo0.Get(vtk.vtkDataObject.DATA_OBJECT())
sh = vtk.vtkShrinkPolyData()
sh.SetInputData(input)
sh.Update()
output.ShallowCopy(sh.GetOutput())
print output
return 1
The source and the filter extract their output from the output information on lines 9 and 20 respectively. Note that these objects are guaranteed to exist and be of type vtkPolyData by the pipeline code. The type is determined by the constructor code, which looks like this:
class MyFilter(VTKPythonAlgorithmBase):
def __init__(self):
VTKPythonAlgorithmBase.__init__(self,
nInputPorts=1, inputType='vtkPolyData',
nOutputPorts=1, outputType='vtkPolyData')
The source uses the request object (line 5) to set the radius of the sphere that it produces (line 7). This is a good example of how source and filters can use the request objects in their RequestData methods (for example to read a particular time step or a spatial subset).
This is it! Hopefully, now you have a good understanding of the inner working of the VTK pipeline. We’ll get to put this knowledge to use in upcoming blogs. You can find the full example on this page. I also recommend taking a look at this blog as it demonstrates how these concepts are used in developing an HDF5 reader.
Berk, thank you very much for this series. I definitely have a better understanding of the inner workings of the pipeline now! The use of Python also makes it easy to modify and see what happens too.
Berk, I know this blog was written quite some time ago but this series of blogs is really the ebst reference I’ve found to help me understand how to leverage the pipeline. There’s something (to be honest, likely many things….) I still don’t understand…
In the example it seems that the Source can only extract the value from requestKey because it has accees to the instance of requestKey that’s created at the top of the file. So it’s able to use that instance to extract the key from the Source outInfo Information object. whereas in a real world example it’s unlikley that the Source would have access to the instance of requestKey.
So how should a Source or Filter extract the key from the Information in the more general case?
In the general use case, there would have to be a central location for the key objects. In C++ VTK, this is done by generating the keys at start time and then accessing them through static members of the class. This is what the key macros do under the covers. Something similar can be done in Python. Or the keys can be part of the module which are created at import time…
THanks Berk – I can now give up on my attempts to do otherwsie….. 🙂
Berk – I know you created this series a while ago, but it;s still the best reference to the pipeline I’ve been able to find. Very helpful indeed.
I have one question about the example though.
The Source is only able to access the value of resultKey because it has access to the instance of resultKey created at the top of the file. In a more general case, it wouldn’t have this access. So how would it extract the key from the vtkInformationVector?
In case it’s not obvious, these comments are duplicates…. There’s a lot of latency between adding a comment and having it show up. More than enopuigh time for me to assume I’d goofed something and that my original comment was lost…..